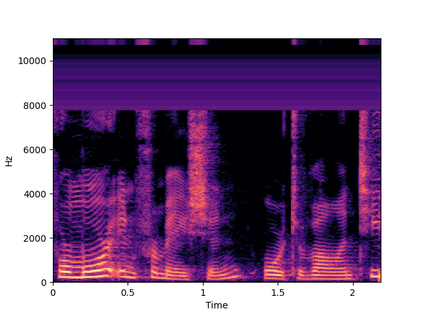
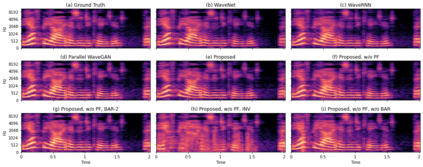
Autoregressive models have achieved outstanding performance in neural speech synthesis tasks. Though they can generate highly natural human speech, the iterative generation inevitably makes the synthesis time proportional to the utterance's length, leading to low efficiency. Many works were dedicated to generating the whole speech time sequence in parallel and then proposed GAN-based, flow-based, and score-based models. This paper proposed a new thought for the autoregressive generation. Instead of iteratively predicting samples in a time sequence, the proposed model performs frequency-wise autoregressive generation (FAR) and bit-wise autoregressive generation (BAR) to synthesize speech. In FAR, a speech utterance is first split into different frequency subbands. The proposed model generates a subband conditioned on the previously generated one. A full band speech can then be reconstructed by using these generated subbands and a synthesis filter bank. Similarly, in BAR, an 8-bit quantized signal is generated iteratively from the first bit. By redesigning the autoregressive method to compute in domains other than the time domain, the number of iterations in the proposed model is no longer proportional to the utterance's length but the number of subbands/bits. The inference efficiency is hence significantly increased. Besides, a post-filter is employed to sample audio signals from output posteriors, and its training objective is designed based on the characteristics of the proposed autoregressive methods. The experimental results show that the proposed model is able to synthesize speech faster than real-time without GPU acceleration. Compared with the baseline autoregressive and non-autoregressive models, the proposed model achieves better MOS and shows its good generalization ability while synthesizing 44 kHz speech or utterances from unseen speakers.
翻译:自动递减模型在神经言语合成任务中取得了杰出的性能。 虽然迭代生成能够产生高度自然的人类言语, 但迭代生成会不可避免地使合成时间与发音长度成比例, 导致低效率。 许多作品都致力于平行生成整个语音时间序列, 然后在 GAN 、 流基和计分模型中生成。 本文为自动递减生成提出了一个新的想法 。 与在时间序列中迭接地预测样本相比, 所拟议的模型是频度自动递减生成的, 和比对的自动递增生成的。 在 FAR 中, 语音递增时间序列将首次拆成不同的频率子带。 在 FAR 中, 语音递增到不同的频率子带 。 所拟议的音速递增的音频度模式比预估值要快得多, 其自动递增的精确度比预估值要快得多, 其预估的自动递增速度比预估量要快, 其预估的机率比预估值要快得多, 其预估的机率比预估的模型/ 更精确度比预估值要快, 。