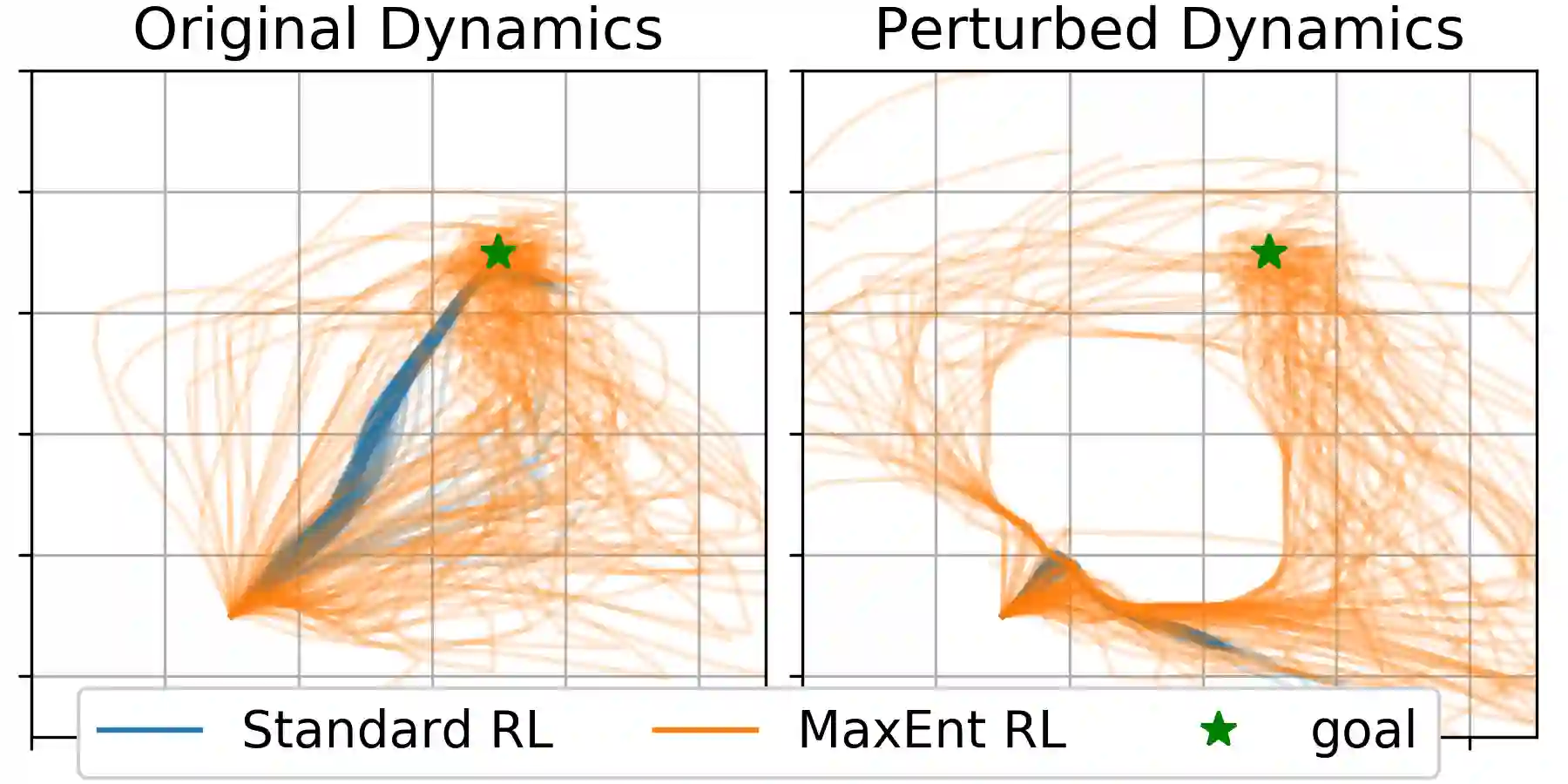
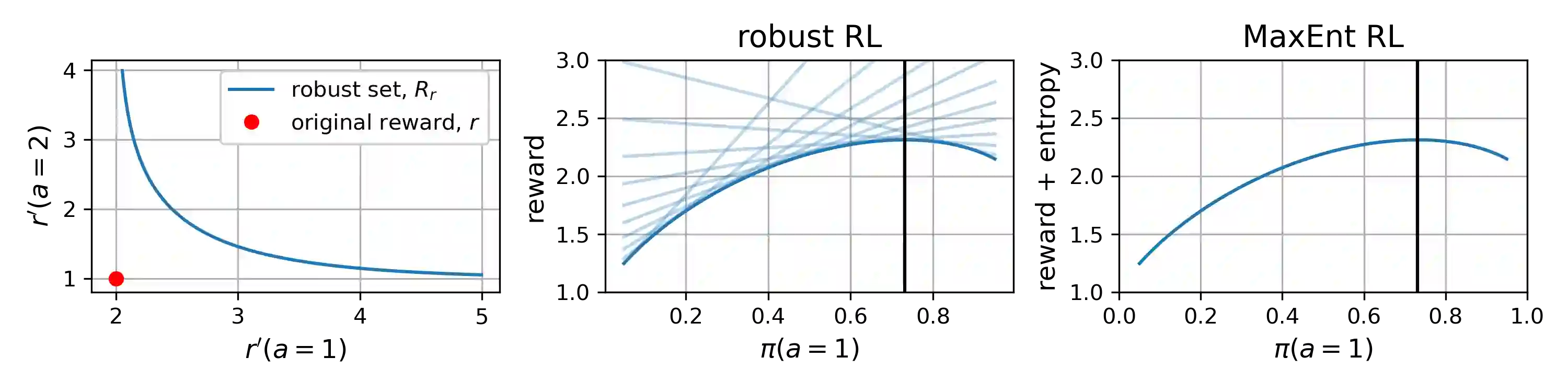
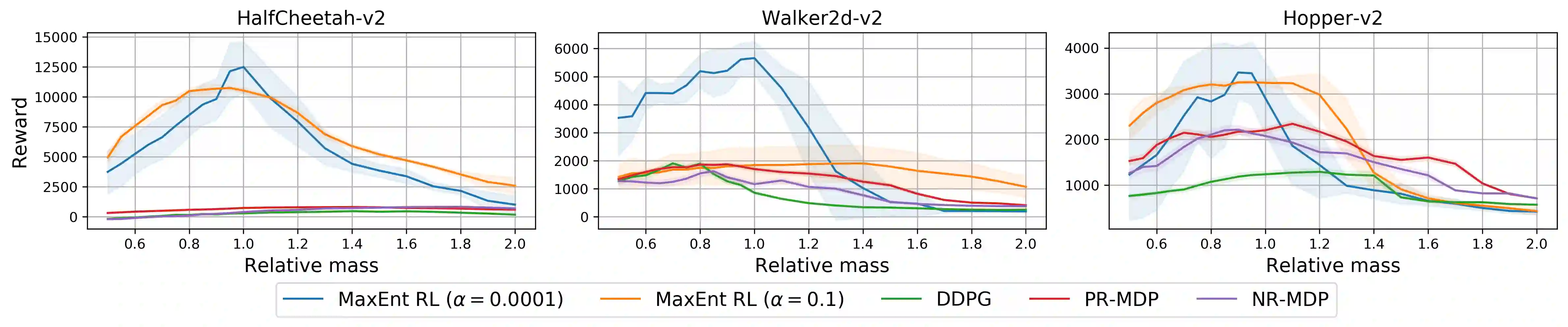
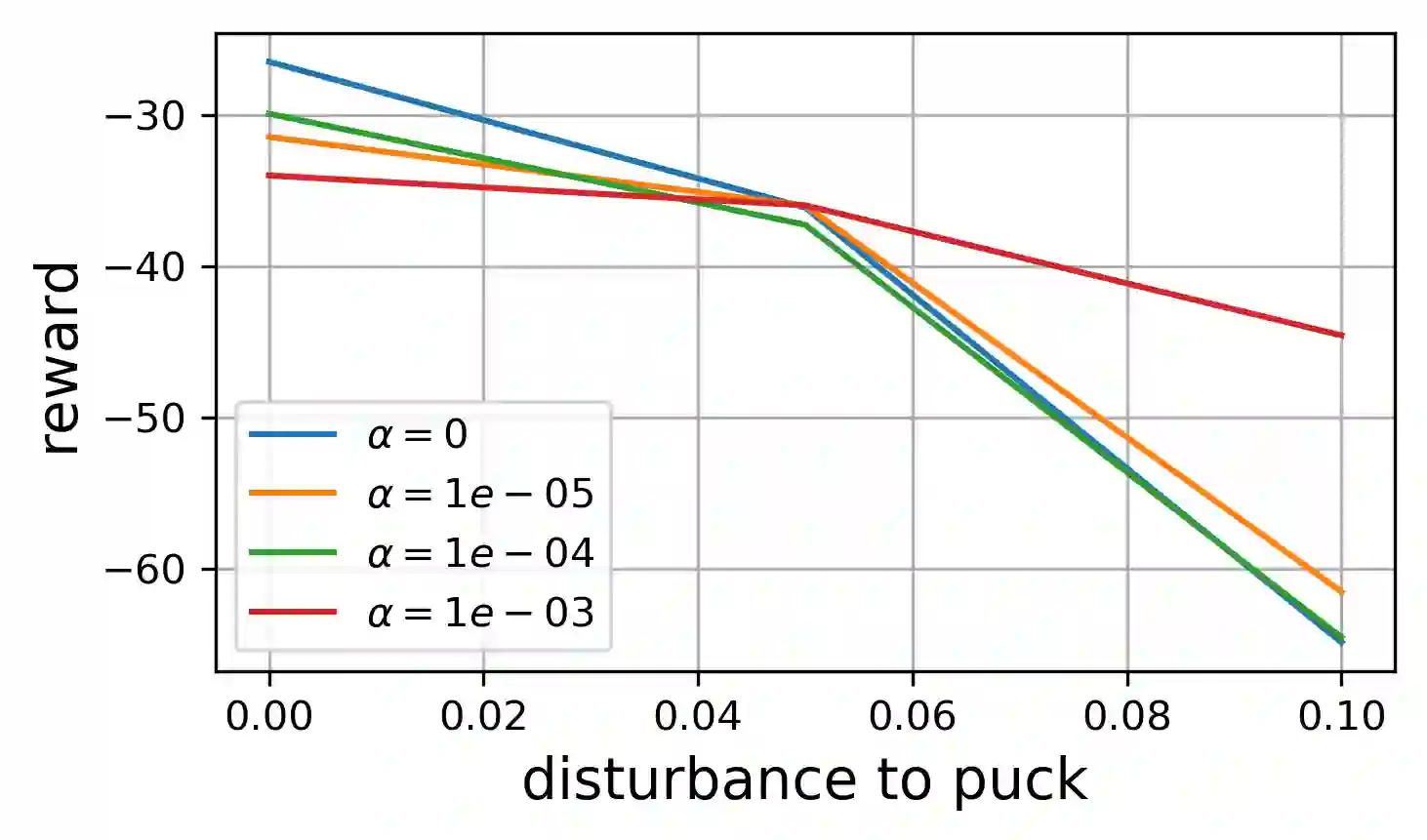
Many potential applications of reinforcement learning (RL) require guarantees that the agent will perform well in the face of disturbances to the dynamics or reward function. In this paper, we prove theoretically that maximum entropy (MaxEnt) RL maximizes a lower bound on a robust RL objective, and thus can be used to learn policies that are robust to some disturbances in the dynamics and the reward function. While this capability of MaxEnt RL has been observed empirically in prior work, to the best of our knowledge our work provides the first rigorous proof and theoretical characterization of the MaxEnt RL robust set. While a number of prior robust RL algorithms have been designed to handle similar disturbances to the reward function or dynamics, these methods typically require additional moving parts and hyperparameters on top of a base RL algorithm. In contrast, our results suggest that MaxEnt RL by itself is robust to certain disturbances, without requiring any additional modifications. While this does not imply that MaxEnt RL is the best available robust RL method, MaxEnt RL is a simple robust RL method with appealing formal guarantees.
翻译:强化学习的许多潜在应用(RL)要求保证代理商在遇到动态或奖励功能的干扰时能够很好地发挥作用。在本文中,我们从理论上证明,在强大的 RL 目标上,最大灵敏(MAxEnt) RL 将最大灵敏(MAxEnt) RL 限制最大化,从而可以用来学习对动态和奖励功能的某些干扰具有强力的政策。虽然在先前的工作中已经从经验上观察到了MaxEnt RL 的这种能力,但我们的工作为我们的知识提供了对MaxEnt RL 强力组合的首次严格证据和理论定性。虽然以前设计了一些强力RL 算法是为了处理与奖励功能或动态类似的扰动,但这些方法通常需要在基准RL 算法的顶部增加移动部件和超参数。相反,我们的结果表明,MaxEnt RL 本身对某些扰动具有强力,而不需要任何额外的修改。这并不意味着MaxEnt RL 是现有最强力RL 方法,但MaxEnt RL 是一种简单有力的RL 方法,可以上诉正式保证。