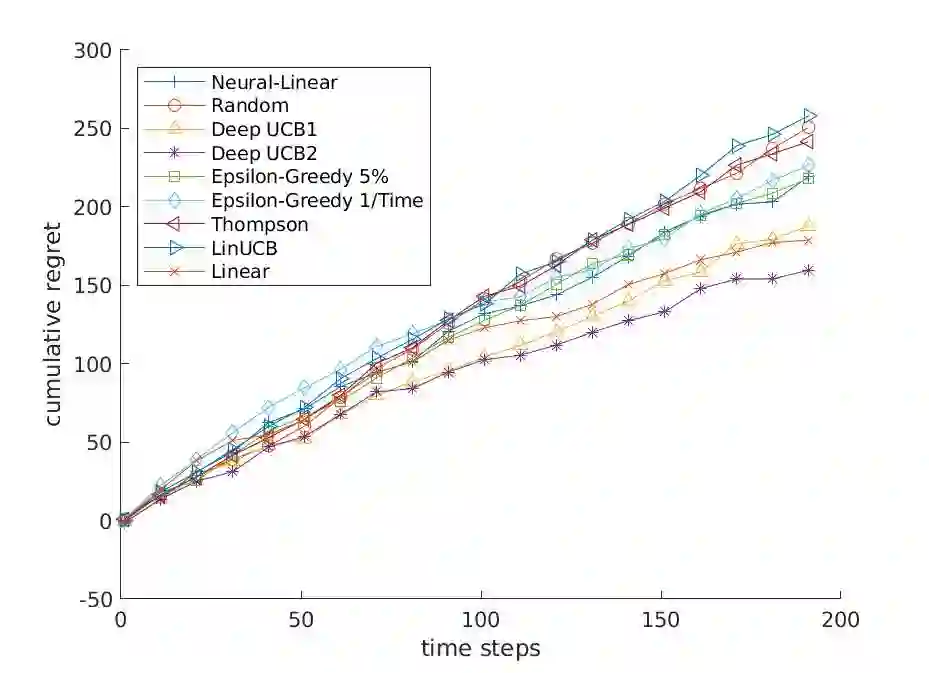
Contextual multi-armed bandits (CMAB) have been widely used for learning to filter and prioritize information according to a user's interest. In this work, we analyze top-K ranking under the CMAB framework where the top-K arms are chosen iteratively to maximize a reward. The context, which represents a set of observable factors related to the user, is used to increase prediction accuracy compared to a standard multi-armed bandit. Contextual bandit methods have mostly been studied under strict linearity assumptions, but we drop that assumption and learn non-linear stochastic reward functions with deep neural networks. We introduce a novel algorithm called the Deep Upper Confidence Bound (UCB) algorithm. Deep UCB balances exploration and exploitation with a separate neural network to model the learning convergence. We compare the performance of many bandit algorithms varying K over real-world data sets with high-dimensional data and non-linear reward functions. Empirical results show that the performance of Deep UCB often outperforms though it is sensitive to the problem and reward setup. Additionally, we prove theoretical regret bounds on Deep UCB giving convergence to optimality for the weak class of CMAB problems.
翻译:多武装大盗(CMAB)被广泛用于学习根据用户的兴趣筛选和优先排序信息。在这项工作中,我们分析了在CMAB框架下的顶级K级算法,即高K武器是迭接式选择,以获得最大限度的奖励。背景是一组与用户有关的可观测因素,用来提高预测准确性,与标准的多武装大盗相比。背景强盗方法大多是在严格的线性假设下研究的,但我们放弃了这一假设,并学习了深神经网络的非线性随机奖赏功能。我们引入了一种新型算法,称为深高层信任算法(UCB) 。深UCB平衡了探索和开发,与一个单独的神经网络进行平衡,以模拟学习趋同。我们用高维数据和非线性奖赏功能对许多不同的K型大盗算法的性进行了比较。实证结果显示,Deep UCB的性能往往超越了对问题敏感度和奖赏设置的完美性。此外,我们证明深UCB在深度UB的理论上有悔。