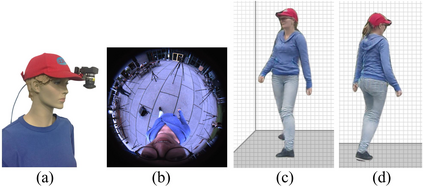
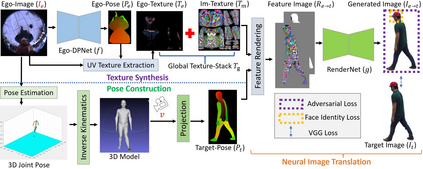
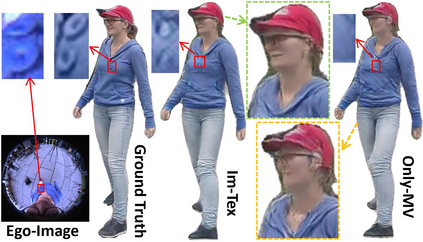
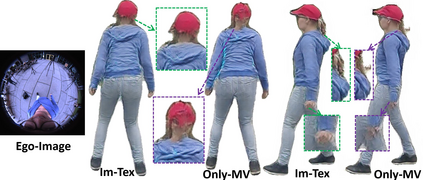
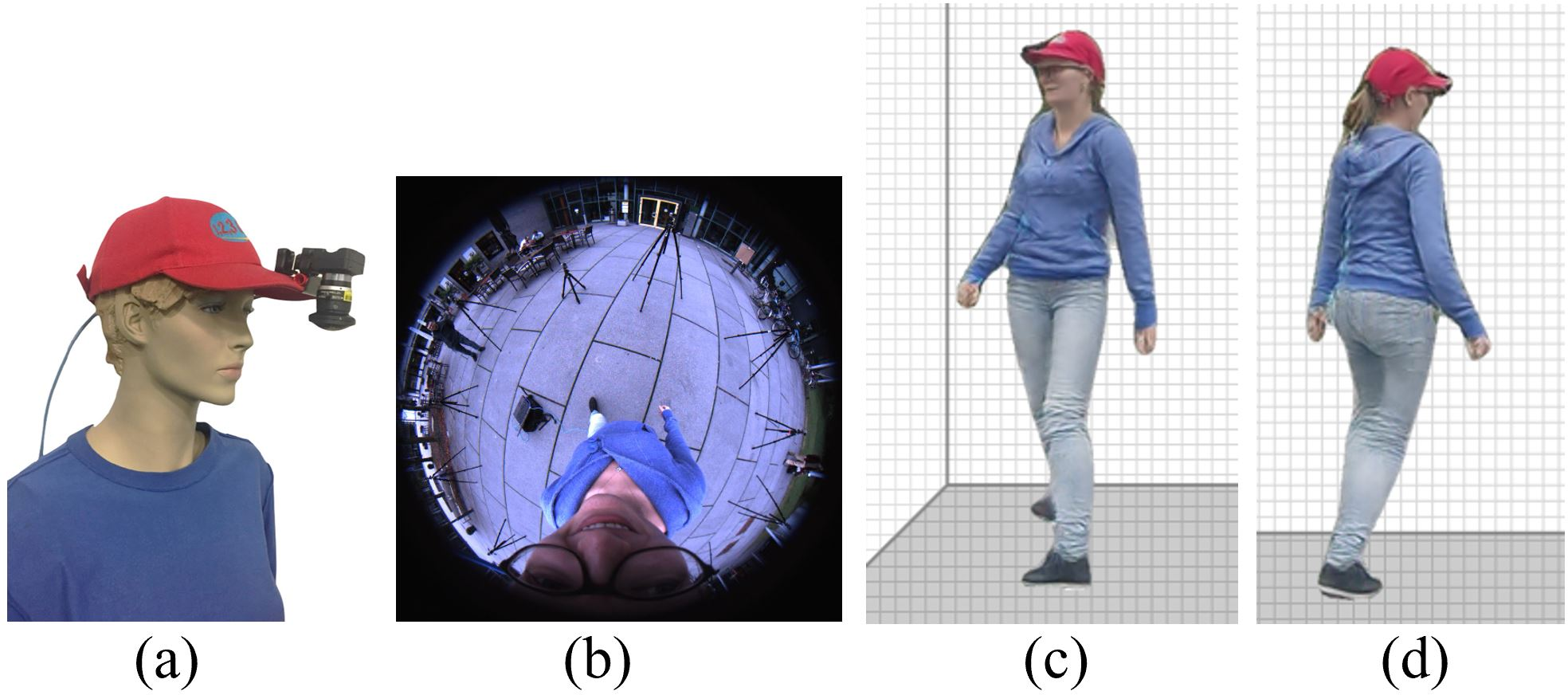
We present EgoRenderer, a system for rendering full-body neural avatars of a person captured by a wearable, egocentric fisheye camera that is mounted on a cap or a VR headset. Our system renders photorealistic novel views of the actor and her motion from arbitrary virtual camera locations. Rendering full-body avatars from such egocentric images come with unique challenges due to the top-down view and large distortions. We tackle these challenges by decomposing the rendering process into several steps, including texture synthesis, pose construction, and neural image translation. For texture synthesis, we propose Ego-DPNet, a neural network that infers dense correspondences between the input fisheye images and an underlying parametric body model, and to extract textures from egocentric inputs. In addition, to encode dynamic appearances, our approach also learns an implicit texture stack that captures detailed appearance variation across poses and viewpoints. For correct pose generation, we first estimate body pose from the egocentric view using a parametric model. We then synthesize an external free-viewpoint pose image by projecting the parametric model to the user-specified target viewpoint. We next combine the target pose image and the textures into a combined feature image, which is transformed into the output color image using a neural image translation network. Experimental evaluations show that EgoRenderer is capable of generating realistic free-viewpoint avatars of a person wearing an egocentric camera. Comparisons to several baselines demonstrate the advantages of our approach.
翻译:我们展示了EgoRenderer, 这个系统用来将一个被一个可磨损的、以自我为中心的鱼眼摄像机所捕获的人的全体神经动因转换成一个系统。 我们的系统将演员的光现实新观点及其运动从任意的虚拟相机位置进行。 由这种以自我为中心的图像产生的全体动因因自上而下视图和巨大的扭曲而带来独特的挑战。 我们通过将演化过程分解成几个步骤来应对这些挑战, 包括将质谱合成、 建构和神经图像翻译。 对于质谱合成, 我们提议Ego- DPNet, 是一个神经网络, 用来推断输入的鱼眼图像和基本准体模型之间的密集对应关系, 以及从自我中心输入的输入中提取的纹理。 此外, 我们的方法还学习了一个隐含的纹理堆, 它可以捕捉到各种面和观点之间的详细外观变化。 我们首先用一个对立的图像模型, 我们然后将一个自由的直观图像网络, 将一个直观的直观图像转换成一个直观图像的直径图像模型。 我们用一个直观的直观图像的直观图像模型将一个直观图像的直观图像图像图像图像图像图像图像图像图像图像图像图像图像图像图像图像图像图像图像图像图像图像模型组合成一个直成一个模型。