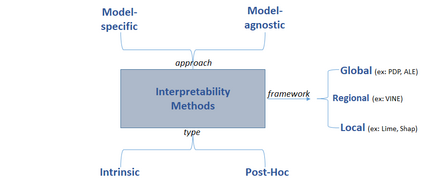
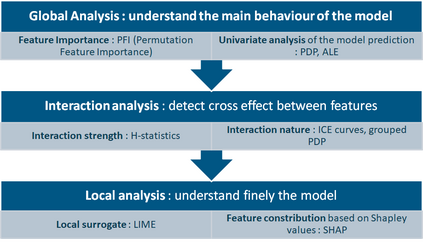
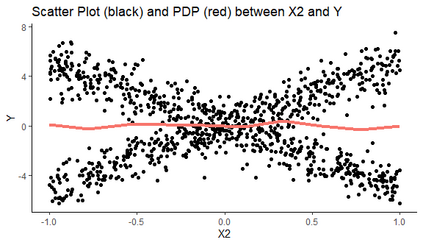
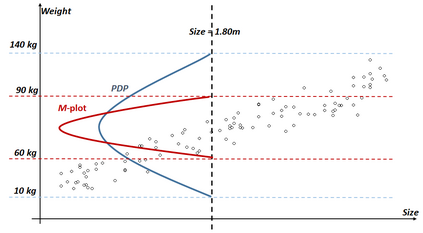
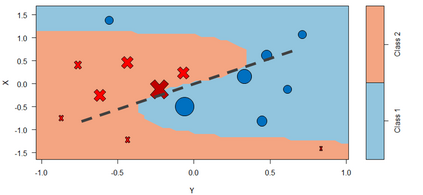
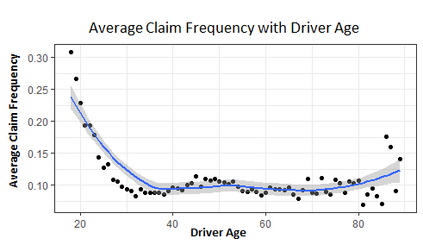
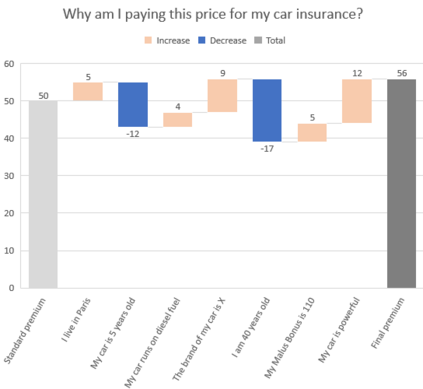
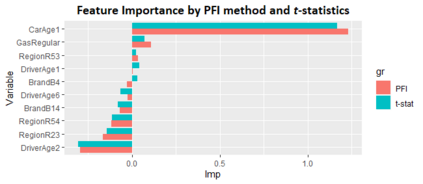
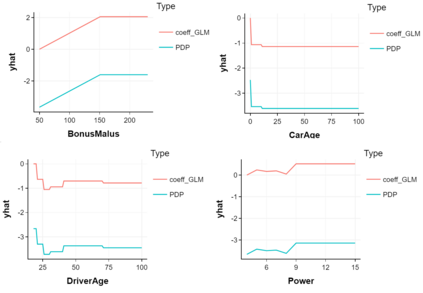
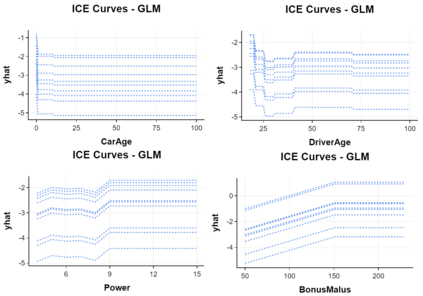
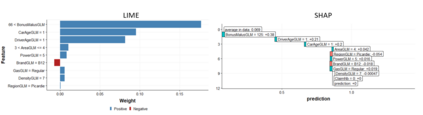
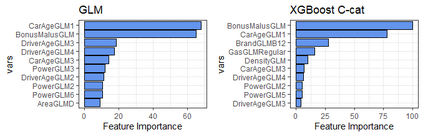
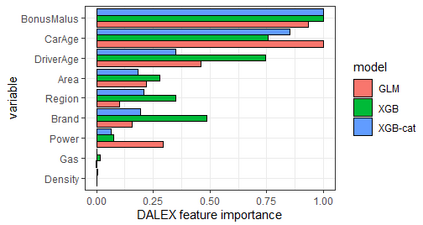
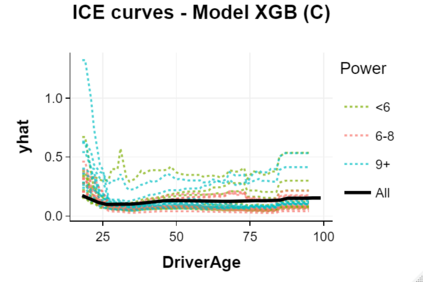
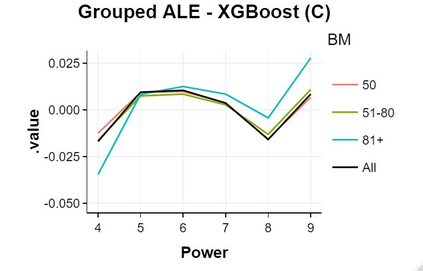
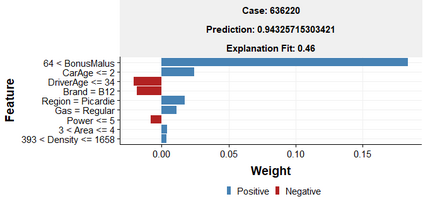
The use of models, even if efficient, must be accompanied by an understanding at all levels of the process that transforms data (upstream and downstream). Thus, needs increase to define the relationships between individual data and the choice that an algorithm could make based on its analysis (e.g. the recommendation of one product or one promotional offer, or an insurance rate representative of the risk). Model users must ensure that models do not discriminate and that it is also possible to explain their results. This paper introduces the importance of model interpretation and tackles the notion of model transparency. Within an insurance context, it specifically illustrates how some tools can be used to enforce the control of actuarial models that can nowadays leverage on machine learning. On a simple example of loss frequency estimation in car insurance, we show the interest of some interpretability methods to adapt explanation to the target audience.
翻译:模型的使用,即使效率高,也必须辅之以对数据转换过程(上游和下游)各级的理解,因此,需要增加数据数量,以界定个人数据与算法根据其分析(例如,一个产品或一个促销报价的建议,或代表风险的保险费率)可作出的选择之间的关系; 模型使用者必须确保模型不歧视,并且也有可能解释其结果; 本文介绍模型解释的重要性,并论述模型透明度的概念; 在保险方面,它特别说明如何使用某些工具来控制目前能够利用机器学习的精算模型; 仅举一个汽车保险损失频率估计的例子,我们表示一些解释性方法有兴趣调整对目标受众的解释。