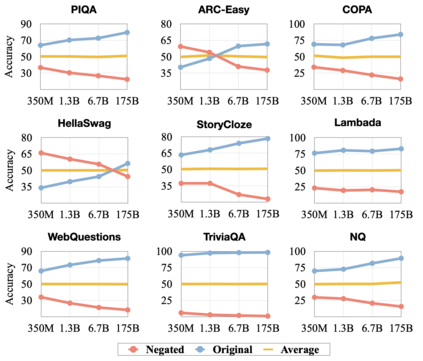
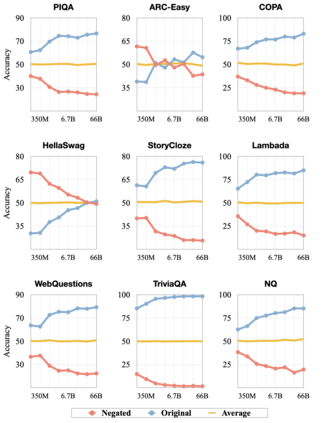
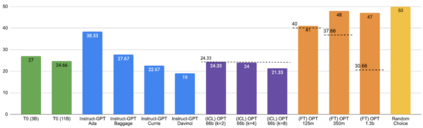
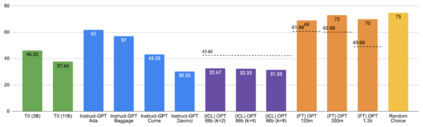
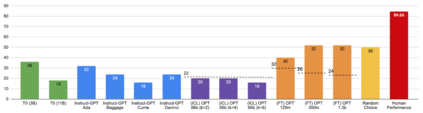
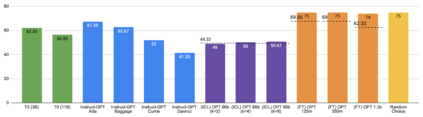
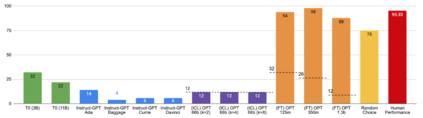
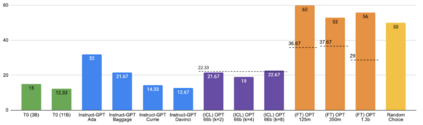
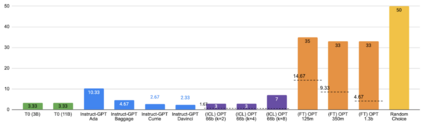
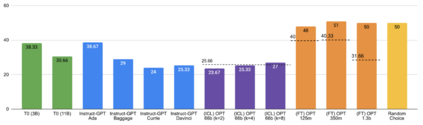
Previous work has shown that there exists a scaling law between the size of Language Models (LMs) and their zero-shot performance on different downstream NLP tasks. In this work, we show that this phenomenon does not hold when evaluating large LMs on tasks with negated prompts, but instead shows an inverse scaling law. We evaluate 9 different tasks with negated prompts on (1) pretrained LMs (OPT & GPT-3) of varying sizes (125M - 175B), (2) LMs further pretrained to generalize to novel prompts (InstructGPT), (3) LMs provided with few-shot examples, and (4) LMs fine-tuned specifically on negated prompts; all LM types perform worse on negated prompts as they scale and show a huge performance gap between the human performance when comparing the average score on both original and negated prompts. By highlighting a critical limitation of existing LMs and methods, we urge the community to develop new approaches of developing LMs that actually follow the given instructions. We provide the code and the datasets to explore negated prompts at https://github.com/joeljang/negated-prompts-for-llms
翻译:先前的工作表明,语言模型的规模及其在下游国家语言模型任务上的零点表现之间存在着一种比例法。在这项工作中,我们表明,在用否定的速率对任务进行大 LMS进行评价时,这种现象并不持久,而是显示了反向比例法。我们评估了9项不同任务,对(1) 不同规模的预先培训LMS(OPT & GPT-3)(125M - 175B),(2) LMS进一步进行了预先培训,以便向新的提示(InstructGPT)推广,(3) LMS提供了少量实例,(4) LMS专门对否定的提示作了微调;所有LMs类型在规模上都表现得更差,在比较原始和否定的速率的平均分时,显示人类业绩之间的巨大业绩差距。我们通过强调现有LMS和方法的关键性限制,敦促社区制定新的方法来发展实际遵循既定指示的LMS。我们提供了代码和数据集,以探索 https://gthubb.com/chomeng-prongnenealne 探反的提示。