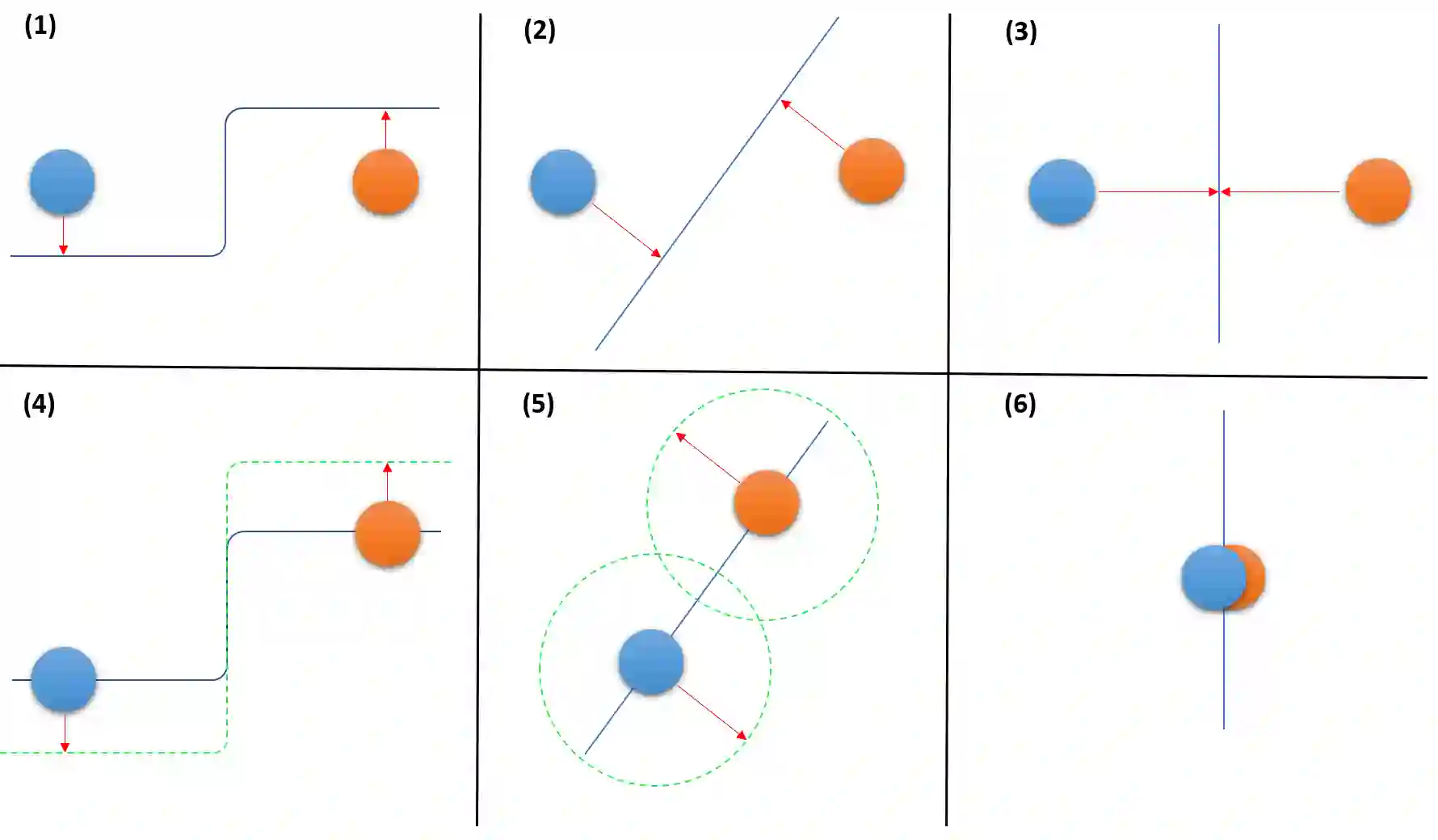
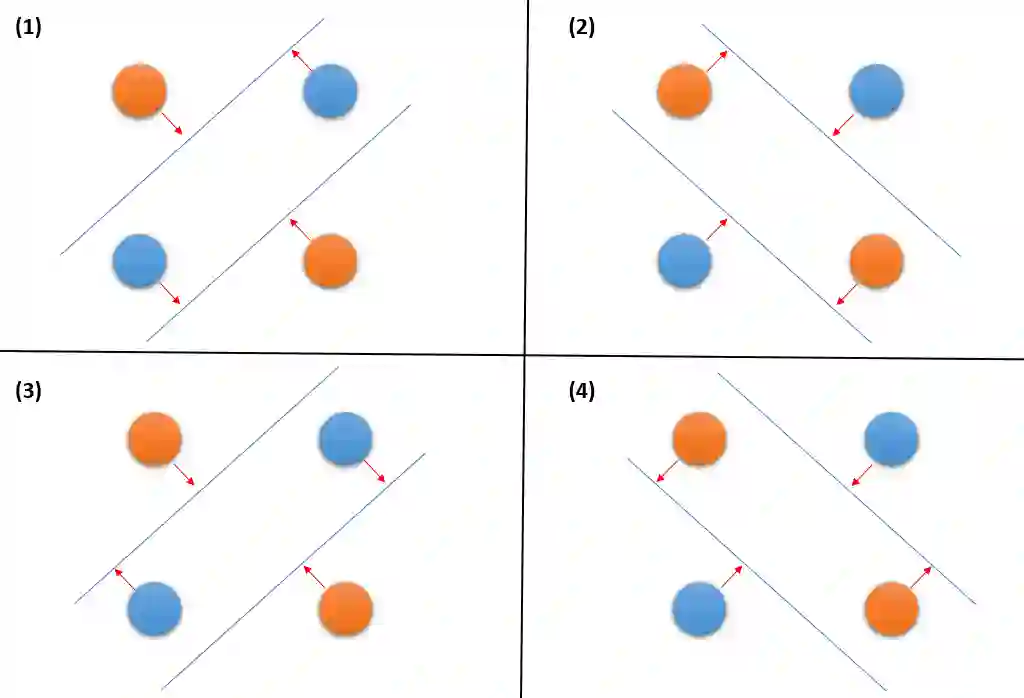
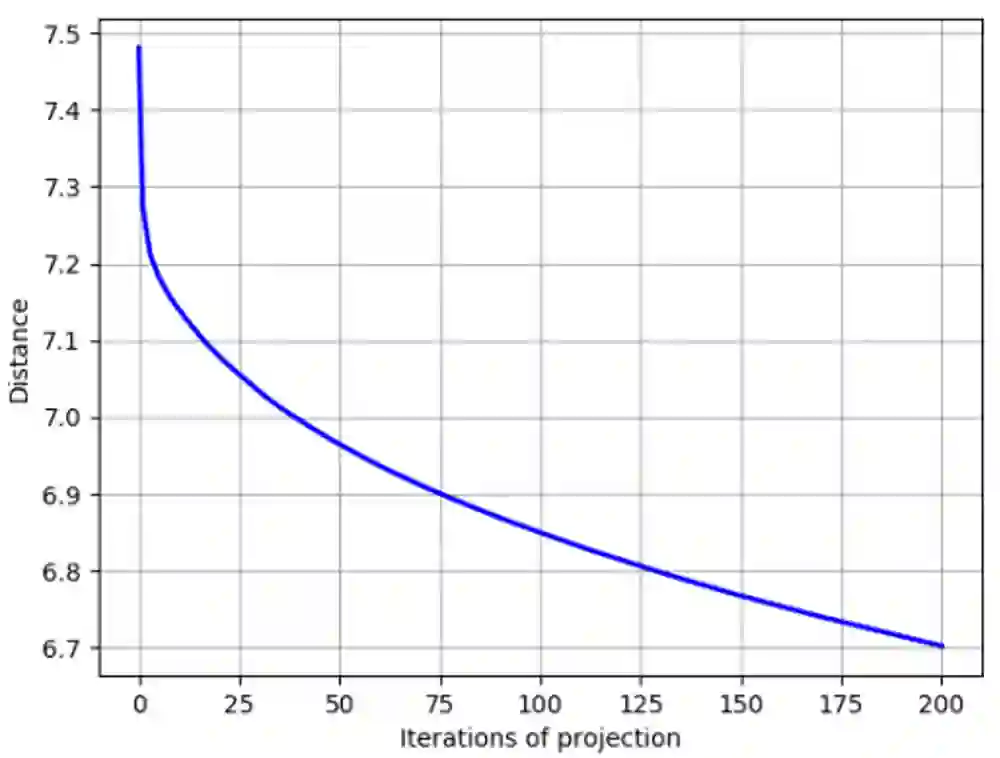
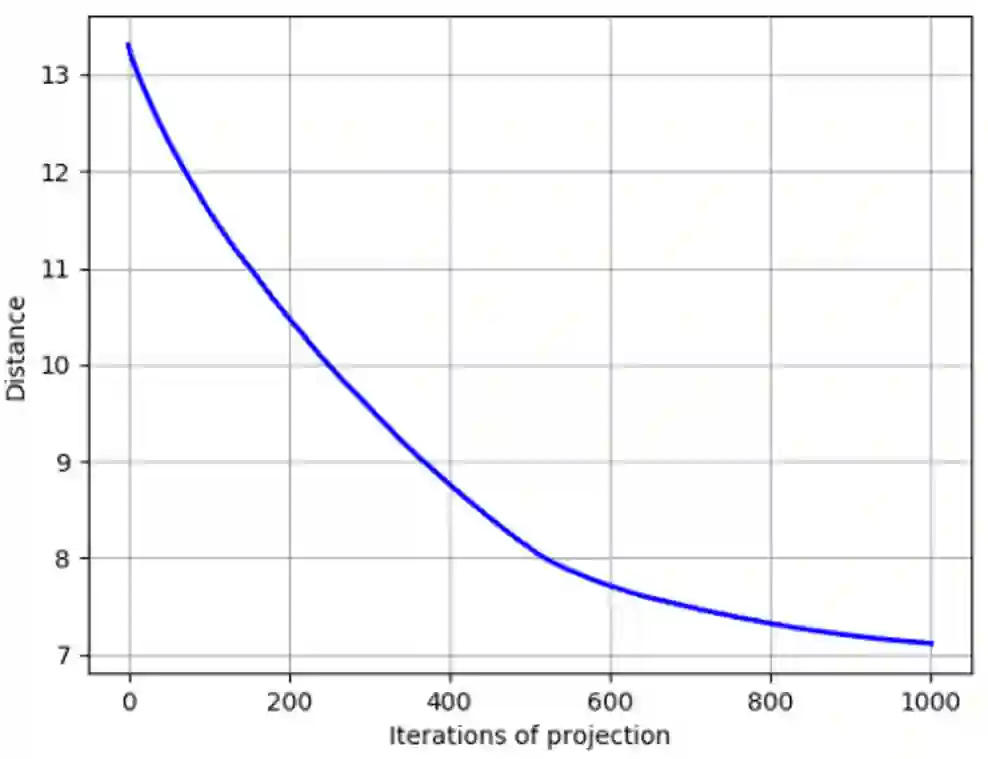
Deep neural networks perform exceptionally well on various learning tasks with state-of-the-art results. While these models are highly expressive and achieve impressively accurate solutions with excellent generalization abilities, they are susceptible to minor perturbations. Samples that suffer such perturbations are known as "adversarial examples". Even though deep learning is an extensively researched field, many questions about the nature of deep learning models remain unanswered. In this paper, we introduce a new conceptual framework attached with a formal description that aims to shed light on the network's behavior and interpret the behind-the-scenes of the learning process. Our framework provides an explanation for inherent questions concerning deep learning. Particularly, we clarify: (1) Why do neural networks acquire generalization abilities? (2) Why do adversarial examples transfer between different models?. We provide a comprehensive set of experiments that support this new framework, as well as its underlying theory.
翻译:深心神经网络在各种学习任务方面表现特别出色,取得了最先进的成果。虽然这些模型具有高度的表达性,并取得了令人印象深刻的准确的解决方案,并且具有极好的概括性能力,但它们很容易受到轻微的干扰。遭受这种扰动的样本被称为“对抗性实例 ” 。 尽管深思熟虑是一个广泛的研究领域,但关于深思广益模式性质的许多问题仍然没有答案。在本文件中,我们引入了一个新的概念框架,并附有正式描述,旨在阐明网络的行为,并解释学习过程的幕后观点。我们的框架为深思熟虑的内在问题提供了解释。特别是,我们澄清:(1) 为什么神经网络获得普遍化能力?(2)为什么在不同模型之间转移对抗性实例?我们提供了一整套支持这一新框架及其基本理论的全面实验。