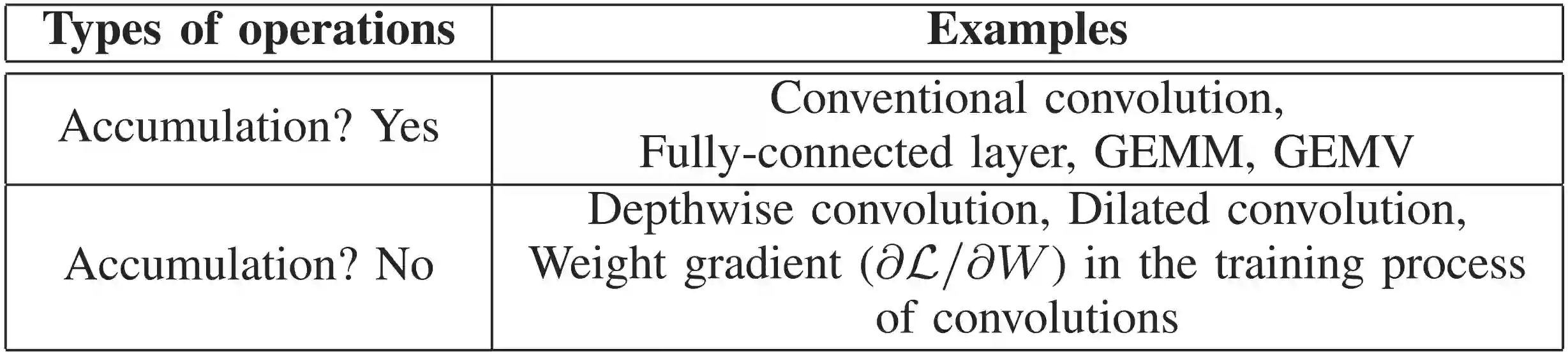
Recognizing the explosive increase in the use of DNN-based applications, several industrial companies developed a custom ASIC (e.g., Google TPU, IBM RaPiD, Intel NNP-I/NNP-T) and constructed a hyperscale cloud infrastructure with it. The ASIC performs operations of the inference or training process of DNN models which are requested by users. Since the DNN models have different data formats and types of operations, the ASIC needs to support diverse data formats and generality for the operations. However, the conventional ASICs do not fulfill these requirements. To overcome the limitations of it, we propose a flexible DNN accelerator called All-rounder. The accelerator is designed with an area-efficient multiplier supporting multiple precisions of integer and floating point datatypes. In addition, it constitutes a flexibly fusible and fissionable MAC array to support various types of DNN operations efficiently. We implemented the register transfer level (RTL) design using Verilog and synthesized it in 28nm CMOS technology. To examine practical effectiveness of our proposed designs, we designed two multiply units and three state-of-the-art DNN accelerators. We compare our multiplier with the multiply units and perform architectural evaluation on performance and energy efficiency with eight real-world DNN models. Furthermore, we compare benefits of the All-rounder accelerator to a high-end GPU card, i.e., NVIDIA GeForce RTX30390. The proposed All-rounder accelerator universally has speedup and high energy efficiency in various DNN benchmarks than the baselines.
翻译:暂无翻译