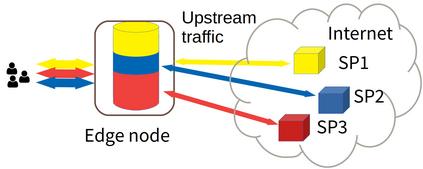
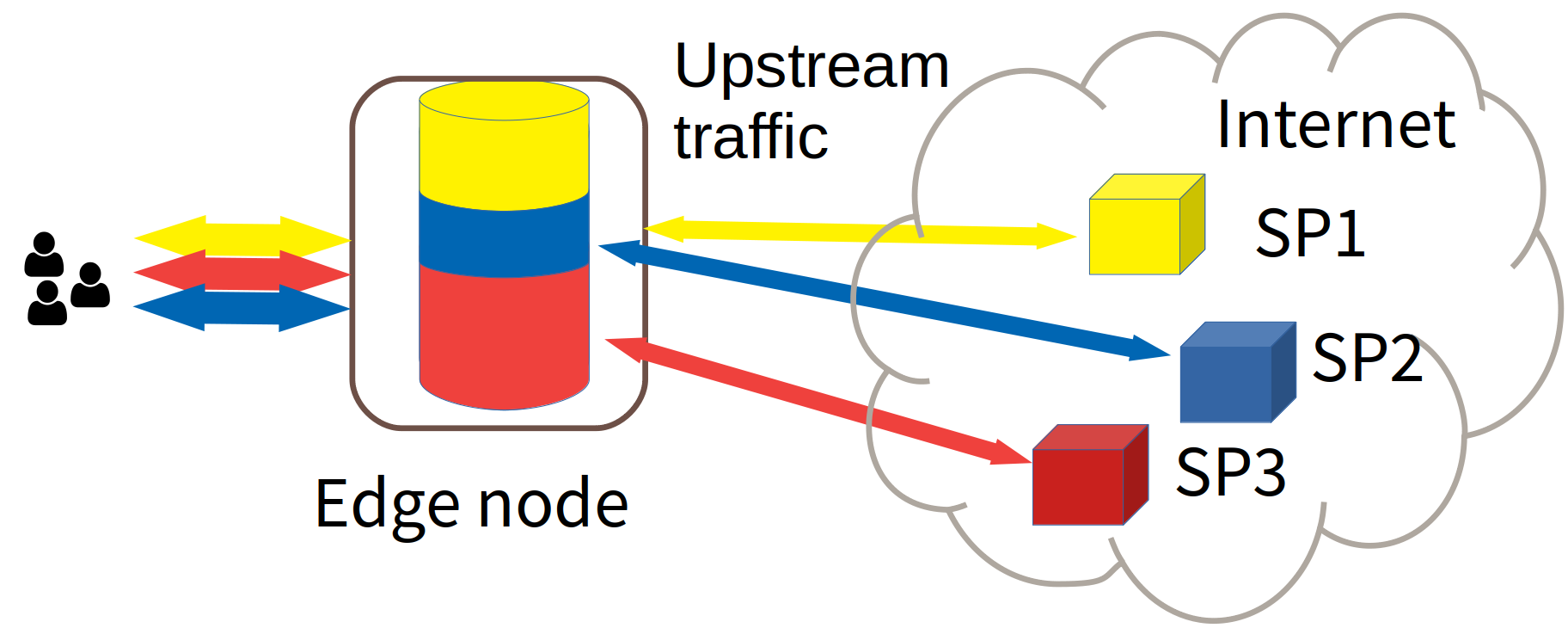
We consider in this work Edge Computing (EC) in a multi-tenant environment: the resource owner, i.e., the Network Operator (NO), virtualizes the resources and lets third party Service Providers (SPs - tenants) run their services, which can be diverse and with heterogeneous requirements. Due to confidentiality guarantees, the NO cannot observe the nature of the traffic of SPs, which is encrypted. This makes resource allocation decisions challenging, since they must be taken based solely on observed monitoring information. We focus on one specific resource, i.e., cache space, deployed in some edge node, e.g., a base station. We study the decision of the NO about how to partition cache among several SPs in order to minimize the upstream traffic. Our goal is to optimize cache allocation using purely data-driven, model-free Reinforcement Learning (RL). Differently from most applications of RL, in which the decision policy is learned offline on a simulator, we assume no previous knowledge is available to build such a simulator. We thus apply RL in an \emph{online} fashion, i.e., the policy is learned by directly perturbing the actual system and monitoring how its performance changes. Since perturbations generate spurious traffic, we also limit them. We show in simulation that our method rapidly converges toward the theoretical optimum, we study its fairness, its sensitivity to several scenario characteristics and compare it with a method from the state-of-the-art.
翻译:在这项工作中,我们考虑的是多租种环境中的边缘计算(EC):资源所有者,即网络操作员(NO),将资源虚拟化,让第三方服务供应商(SPs-租户)管理其服务,这种服务可以是多样化的,并且有多种多样的要求。由于保密保证,NO无法观察加密的SP的交通性质。这使得资源分配决定具有挑战性,因为这些决定必须完全基于观测到的监测信息。我们侧重于一个特定的资源,即缓存空间,部署在某个边缘节点,例如一个基地站。我们研究NO如何在几个SPs之间分配缓存特性的决定,以尽量减少上游交通。我们的目标是利用纯粹的数据驱动的、不使用模型的加强学习(RL)优化缓存分配。不同于RL的大多数应用,在这个应用中,决定政策在模拟器上从离线上学习,我们假定没有以前的知识来建立这样的模拟器。我们因此将RL应用到一个精准的精确度,在模拟系统中,我们通过精确的比对它进行比对速度的精确度, 并且通过它的方式,我们通过一个快速的模拟的模拟方法来显示其业绩。