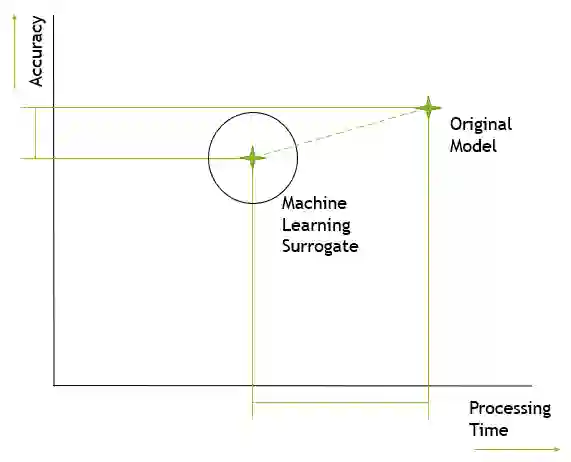
We demonstrate the adaption of three established methods to the field of surrogate machine learning model development. These methods are data augmentation, custom loss functions and transfer learning. Each of these methods have seen widespread use in the field of machine learning, however, here we apply them specifically to surrogate machine learning model development. The machine learning model that forms the basis behind this work was intended to surrogate a traditional engineering model used in the UK nuclear industry. Previous performance of this model has been hampered by poor performance due to limited training data. Here, we demonstrate that through a combination of additional techniques, model performance can be significantly improved. We show that each of the aforementioned techniques have utility in their own right and in combination with one another. However, we see them best applied as part of a transfer learning operation. Five pre-trained surrogate models produced prior to this research were further trained with an augmented dataset and with our custom loss function. Through the combination of all three techniques, we see an improvement of at least $38\%$ in performance across the five models.
翻译:我们展示了三种既定方法适应代用机器学习模型开发领域的情况。这些方法包括数据增强、自定义损失功能和转让学习。这些方法中,每一种方法在机器学习领域都得到了广泛使用。然而,我们在这里专门将其应用于代用机器学习模型开发。作为这项工作基础的机器学习模型旨在替代联合王国核工业使用的传统工程模型。这一模型以往的性能因培训数据有限而受到不良的阻碍。这里,我们通过结合其他技术,模型性能可以大大改进。我们证明,上述每种技术本身和相互结合都具有实用性。然而,我们认为,这些技术最好作为转让学习操作的一部分加以应用。在这项研究之前制作的五个经过预先训练的代用模型经过进一步培训,并配有强化的数据集和我们的自定义损失功能。通过所有三种技术的结合,我们看到在五个模型的性能方面至少改进了38美元。