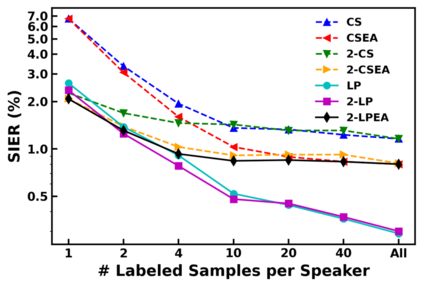
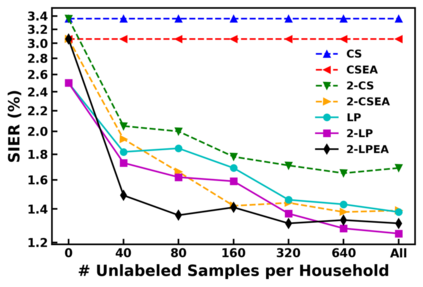
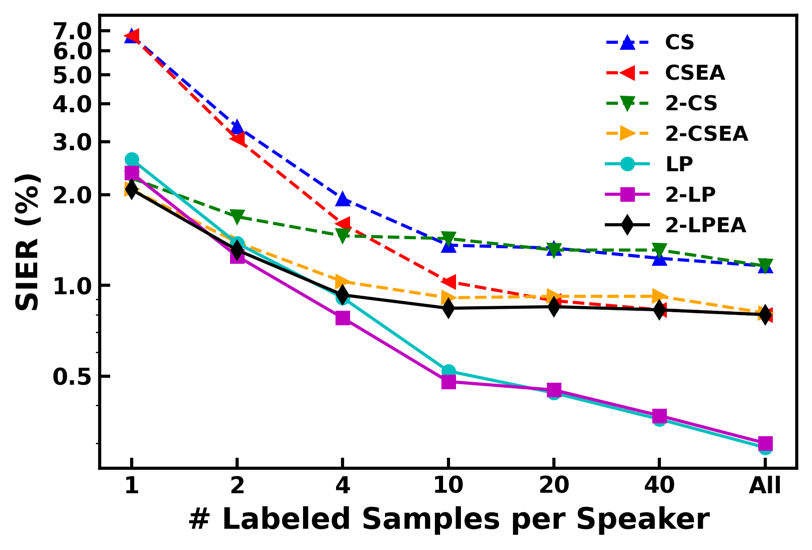
Speaker identification in the household scenario (e.g., for smart speakers) is typically based on only a few enrollment utterances but a much larger set of unlabeled data, suggesting semisupervised learning to improve speaker profiles. We propose a graph-based semi-supervised learning approach for speaker identification in the household scenario, to leverage the unlabeled speech samples. In contrast to most of the works in speaker recognition that focus on speaker-discriminative embeddings, this work focuses on speaker label inference (scoring). Given a pre-trained embedding extractor, graph-based learning allows us to integrate information about both labeled and unlabeled utterances. Considering each utterance as a graph node, we represent pairwise utterance similarity scores as edge weights. Graphs are constructed per household, and speaker identities are propagated to unlabeled nodes to optimize a global consistency criterion. We show in experiments on the VoxCeleb dataset that this approach makes effective use of unlabeled data and improves speaker identification accuracy compared to two state-of-the-art scoring methods as well as their semi-supervised variants based on pseudo-labels.
翻译:在家庭情况中,主讲人身份(例如,智能发言者)通常仅基于少数几句注册语句,但有大得多的一组未贴标签的数据,建议采用半监督的学习方法来改进演讲人的简况。我们提议了一种基于图形的半监督的学习方法,用于在家庭情况中识别发言者身份,以利用未贴标签的语音样本。与大多数发言者认识到侧重于发言者差异性嵌入标准的工作不同,这项工作侧重于语音标签标签推断(比照)。鉴于预先培训的嵌入提取器(比照),基于图形的学习使我们能够整合关于标签和未贴标签的言语的信息。考虑到每个词的图表节点,我们将配对的超音率分作为边距加权。图表是按住户构造的,发言者身份被传播为未贴标签的节点,以优化全球一致性标准。我们在VoxCeeleb数据集的实验中显示,这种方法能够有效利用未贴标签的数据,并提高演讲人的识别准确度,而与两种状态的评分数方法相比,我们以半监督的变式为基础,作为准的准的标签变式。