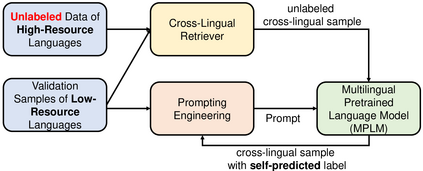
Multilingual Pretrained Language Models (MPLMs) have shown their strong multilinguality in recent empirical cross-lingual transfer studies. In this paper, we propose the Prompts Augmented by Retrieval Crosslingually (PARC) pipeline to improve the zero-shot performance on low-resource languages (LRLs) by augmenting the context with semantically similar sentences retrieved from a high-resource language (HRL) as prompts. PARC improves the zero-shot performance on three downstream tasks (binary sentiment classification, topic categorization and natural language inference) with multilingual parallel test sets across 10 LRLs covering 6 language families in both unlabeled settings (+5.1%) and labeled settings (+16.3%). PARC-labeled also outperforms the finetuning baseline by 3.7%. We find a significant positive correlation between cross-lingual transfer performance on one side, and the similarity between the high- and low-resource languages as well as the amount of low-resource pretraining data on the other side. A robustness analysis suggests that PARC has the potential to achieve even stronger performance with more powerful MPLMs.
翻译:在最近的实证跨语言传输研究中,多语言预先培训语言模型(MPLM)显示了其强大的多语言性能。在本文件中,我们建议通过检索跨语言语言(PARC)管道加速提高低资源语言(LLLs)的零点性能,方法是通过从高资源语言(HRL)中快速检索的语义相似的句子来提高背景。PARC改进了三种下游任务(双感、专题分类和自然语言推论)的零点性能,在10个LLL(包括无标签环境(+5.1%)和标签环境(+16.3%)的6个语言家庭)的多语言平行测试套件中,我们建议PAR的标签也比微调基线高出3.7%。我们发现,一方面的跨语言转移性能与高资源语言和低资源语言之间的相似性能以及另一方的低资源预培训数据数量之间有着显著的积极关系。稳健的分析表明,PARC有可能以更强大的MPLMs取得更强有力的性能。