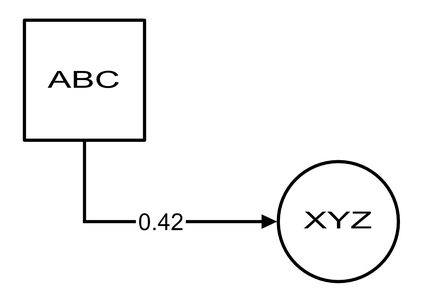
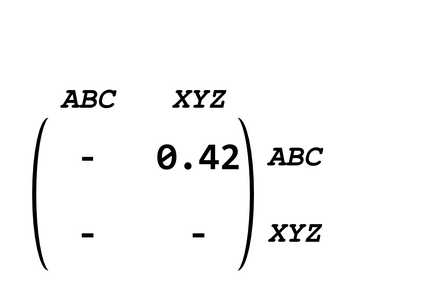
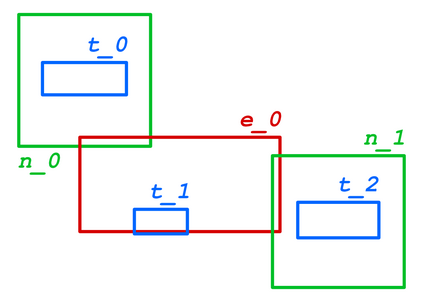
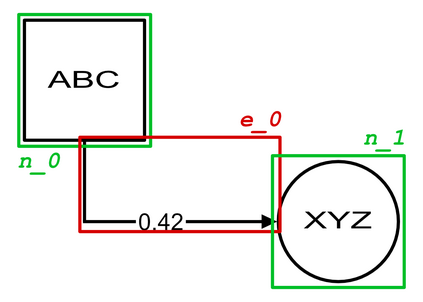
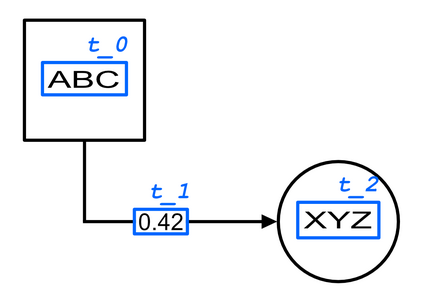
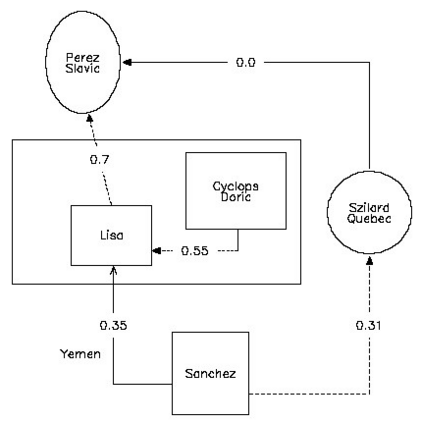
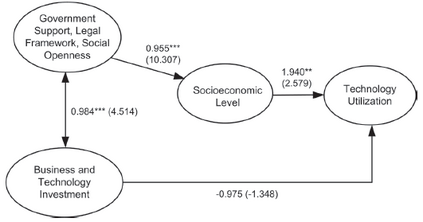
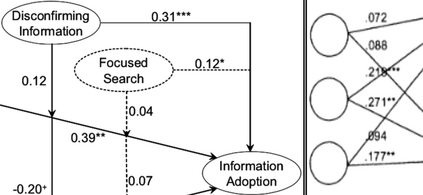
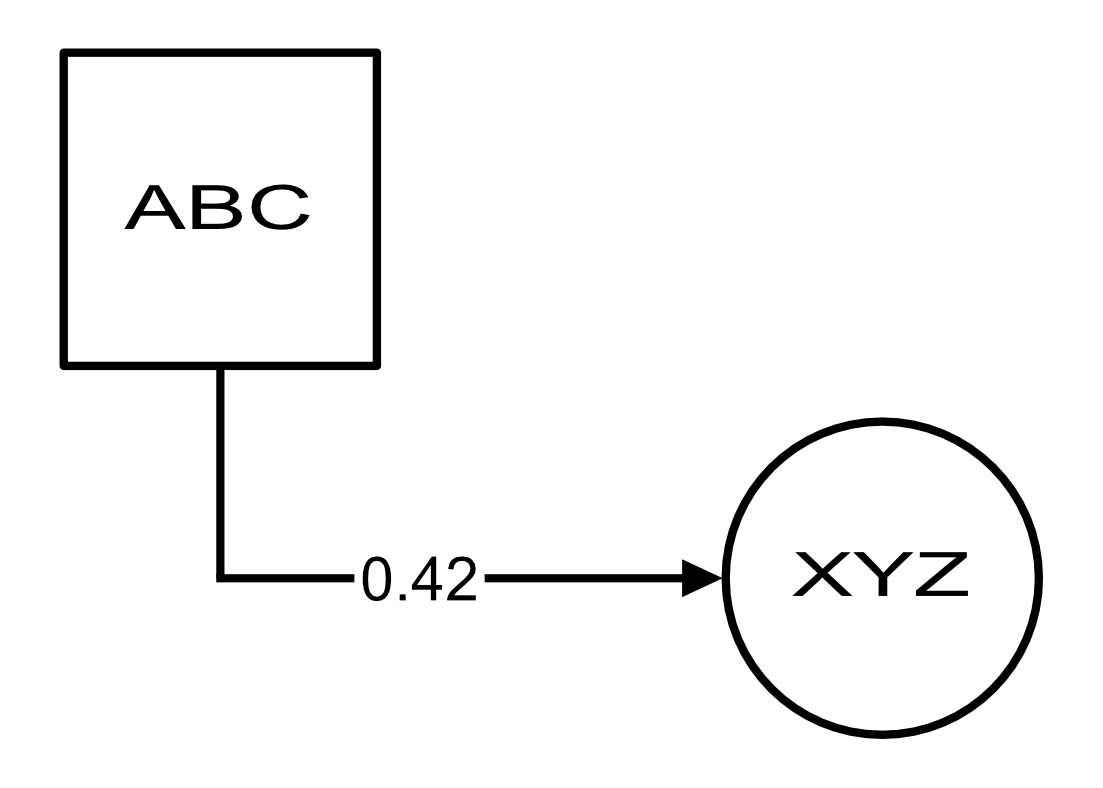
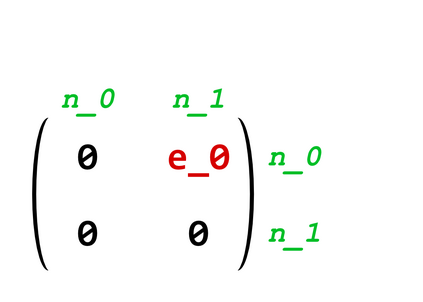Structured Visual Content (SVC) such as graphs, flow charts, or the like are used by authors to illustrate various concepts. While such depictions allow the average reader to better understand the contents, images containing SVCs are typically not machine-readable. This, in turn, not only hinders automated knowledge aggregation, but also the perception of displayed in-formation for visually impaired people. In this work, we propose a synthetic dataset, containing SVCs in the form of images as well as ground truths. We show the usage of this dataset by an application that automatically extracts a graph representation from an SVC image. This is done by training a model via common supervised learning methods. As there currently exist no large-scale public datasets for the detailed analysis of SVC, we propose the Synthetic SVC (SSVC) dataset comprising 12,000 images with respective bounding box annotations and detailed graph representations. Our dataset enables the development of strong models for the interpretation of SVCs while skipping the time-consuming dense data annotation. We evaluate our model on both synthetic and manually annotated data and show the transferability of synthetic to real via various metrics, given the presented application. Here, we evaluate that this proof of concept is possible to some extend and lay down a solid baseline for this task. We discuss the limitations of our approach for further improvements. Our utilized metrics can be used as a tool for future comparisons in this domain. To enable further research on this task, the dataset is publicly available at https://bit.ly/3jN1pJJ
翻译:作者们使用图表、 流程图等结构结构视觉内容( SVC) 来说明各种概念。 虽然这些描述使普通读者能够更好地了解内容, 但包含 SVC 的图像通常无法机器读取。 这不但阻碍自动知识聚合, 也妨碍视障人士对显示的内装图像的感知。 在这项工作中, 我们提出一个合成数据集, 包含图像形式的 SVC 以及地面真相。 我们通过一个自动从 SVC 图像中提取图表表示的应用程序来显示这个数据集的用途。 这是通过共同监督的学习方法培训一个模型来完成的。 由于目前没有大型的SVC 详细分析公共数据集, 我们提议SVC (SSVC) 由12 000 个图像组成的合成数据集, 包含相应的捆绑框说明和详细的图表表解。 我们的数据集可以让SVC 进一步开发强有力的模型来解释 SVC, 同时跳过耗时密度的数据注释。 我们通过共同监督的学习方法来评估一个模型。 我们的合成和手动的模型, 将这个模型用来进行真正的基准的转换。