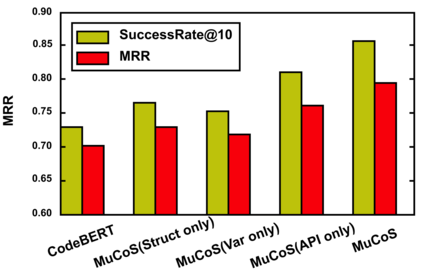
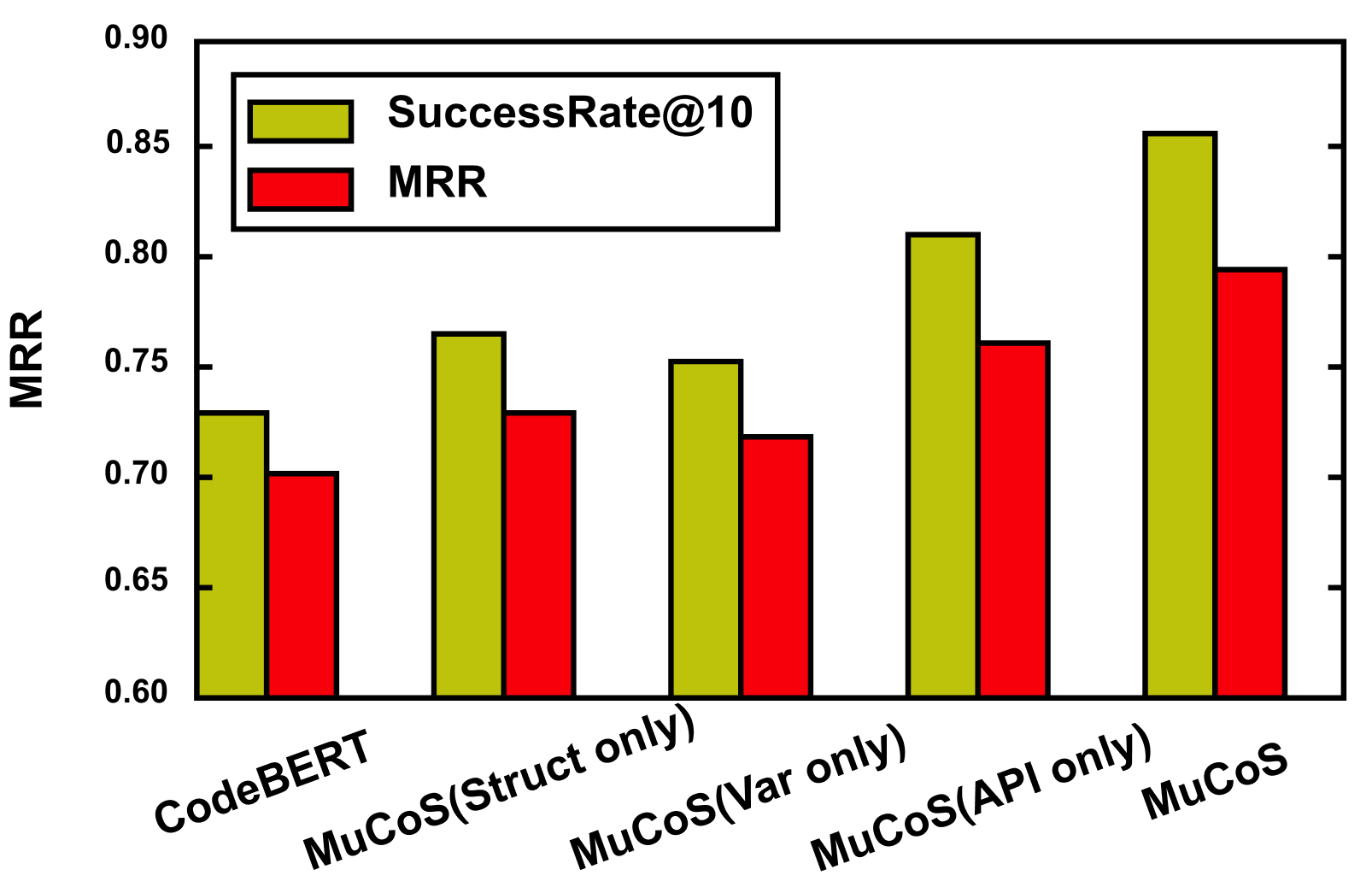
Recently, deep learning methods have become mainstream in code search since they do better at capturing semantic correlations between code snippets and search queries and have promising performance. However, code snippets have diverse information from different dimensions, such as business logic, specific algorithm, and hardware communication, so it is hard for a single code representation module to cover all the perspectives. On the other hand, as a specific query may focus on one or several perspectives, it is difficult for a single query representation module to represent different user intents. In this paper, we propose MuCoS, a multi-model ensemble learning architecture for semantic code search. It combines several individual learners, each of which emphasizes a specific perspective of code snippets. We train the individual learners on different datasets which contain different perspectives of code information, and we use a data augmentation strategy to get these different datasets. Then we ensemble the learners to capture comprehensive features of code snippets.
翻译:最近,深层次的学习方法在代码搜索中成为主流,因为它们在捕捉代码片断和搜索查询之间的语义相关性方面做得更好,并且具有良好的性能。然而,代码片断具有不同层面的不同信息,例如商业逻辑、特定算法和硬件通信,因此单层代码代表模块很难涵盖所有观点。另一方面,由于具体询问可能侧重于一个或几个角度,因此单层查询代表模块很难代表不同的用户意图。在本文中,我们提议 MuCOS,这是一个多模型共同学习架构,用于语言代码搜索。它将几个个体学习者结合在一起,其中每个学习者都强调代码片断的具体视角。我们用包含不同代码信息视角的不同数据集培训个体学习者,我们用数据增强战略获取这些不同的数据集。然后我们召集学习者来捕捉代码片断的综合特征。