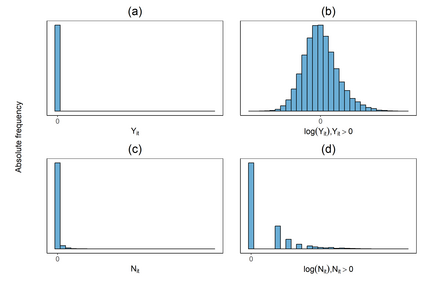
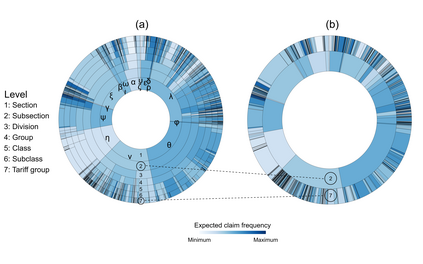
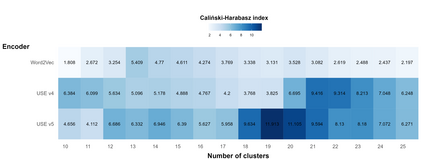
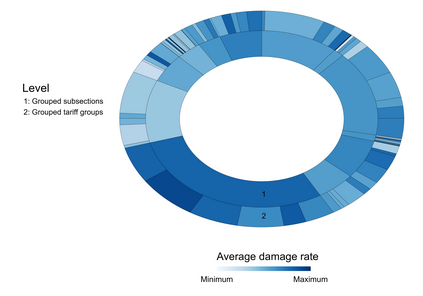
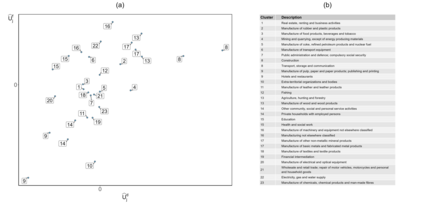
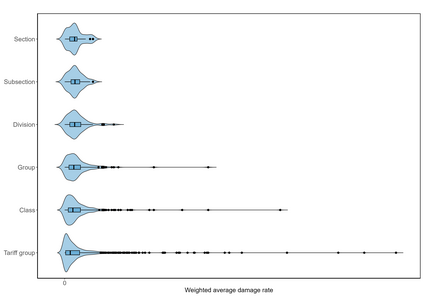
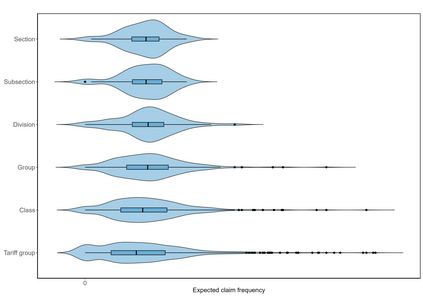
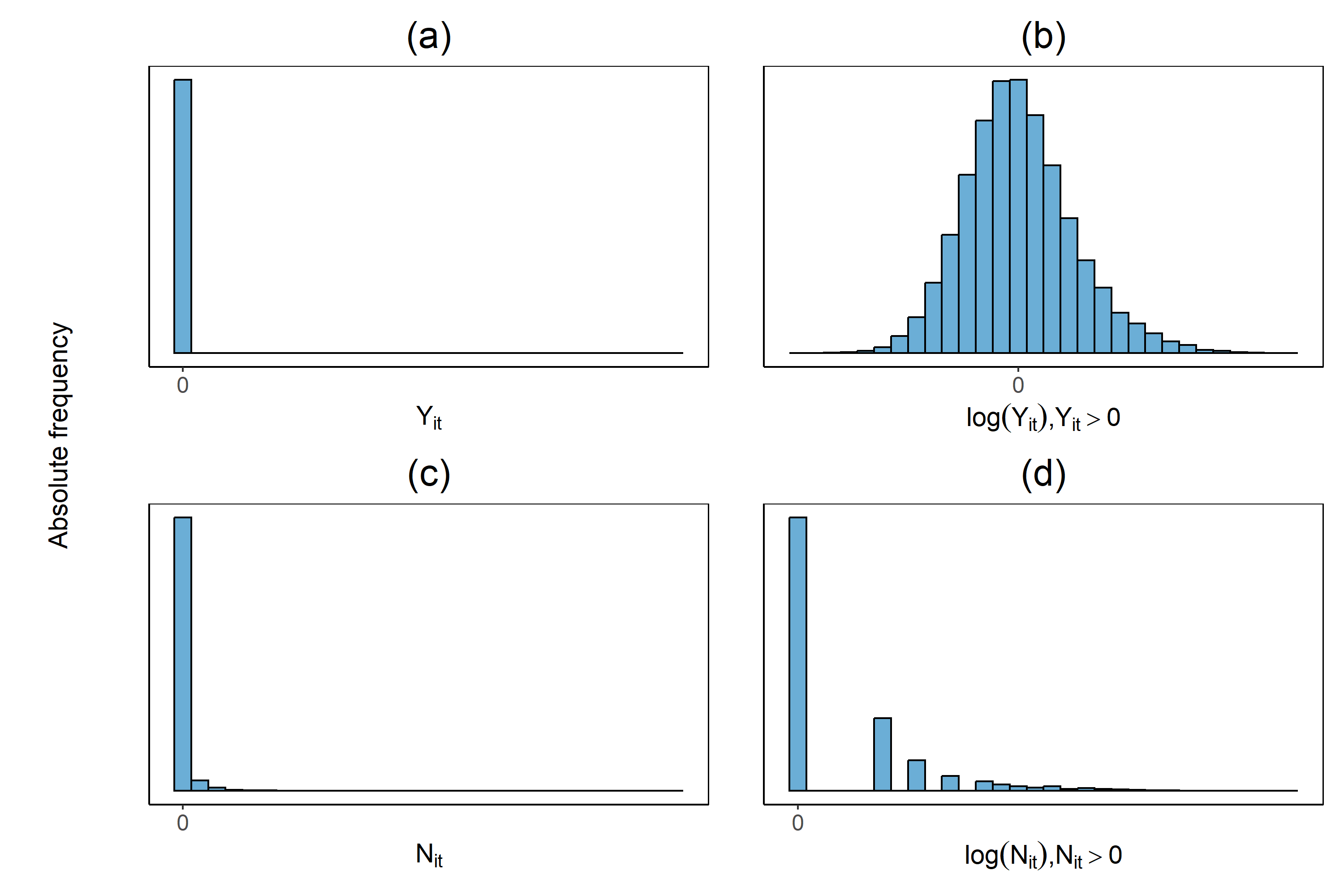
Handling nominal covariates with a large number of categories is challenging for both statistical and machine learning techniques. This problem is further exacerbated when the nominal variable has a hierarchical structure. The industry code in a workers' compensation insurance product is a prime example hereof. We commonly rely on methods such as the random effects approach (Campo and Antonio, 2023) to incorporate these covariates in a predictive model. Nonetheless, in certain situations, even the random effects approach may encounter estimation problems. We propose the data-driven Partitioning Hierarchical Risk-factors Adaptive Top-down (PHiRAT) algorithm to reduce the hierarchically structured risk factor to its essence, by grouping similar categories at each level of the hierarchy. We work top-down and engineer several features to characterize the profile of the categories at a specific level in the hierarchy. In our workers' compensation case study, we characterize the risk profile of an industry via its observed damage rates and claim frequencies. In addition, we use embeddings (Mikolov et al., 2013; Cer et al., 2018) to encode the textual description of the economic activity of the insured company. These features are then used as input in a clustering algorithm to group similar categories. We show that our method substantially reduces the number of categories and results in a grouping that is generalizable to out-of-sample data. Moreover, when estimating the technical premium of the insurance product under study as a function of the clustered hierarchical risk factor, we obtain a better differentiation between high-risk and low-risk companies.
翻译:处理具有大量类别的名义协变量对于统计和机器学习技术都具有挑战性,特别是当名义变量具有分层结构时更加困难。工伤赔偿保险产品中的行业代码正是一个典型的例子。我们通常依靠随机效应方法(Campo和Antonio,2023)来将这些协变量纳入预测模型。然而,在某些情况下,即使随机效应方法也可能遇到估计问题。我们提出了数据驱动的划分分层风险因素自适应自上而下(PHiRAT)算法,将分层结构风险因素减少到其实质,通过将每个层次中类似的类别分组。我们从上而下工作,设计了几个特征来描述层次结构的特定级别中类别的概况。在我们的工伤赔偿案例研究中,我们通过其观察到的损害率和索赔频率来表征行业的风险概况。此外,我们使用嵌入(Mikolov等,2013; Cer等,2018)来编码被保险公司的经济活动的文本描述。然后将这些特征用作输入,用聚类算法将类似的类别分组。我们证明了我们的方法大大减少了类别数量,并导致一个可推广到样本外数据的分组。此外,当将所研究的保险产品的技术保费估计作为分组分层风险因素的函数时,我们获得了更好的高风险和低风险公司之间的区分。