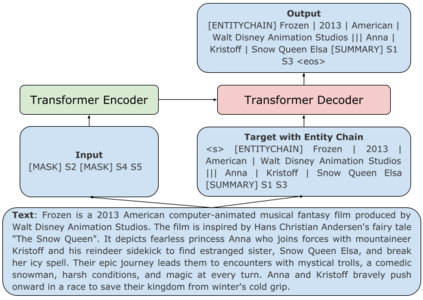
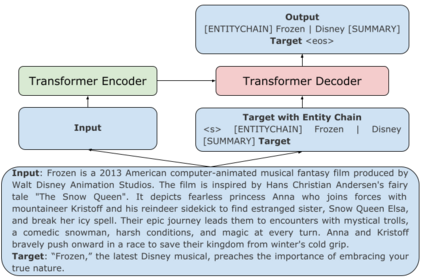
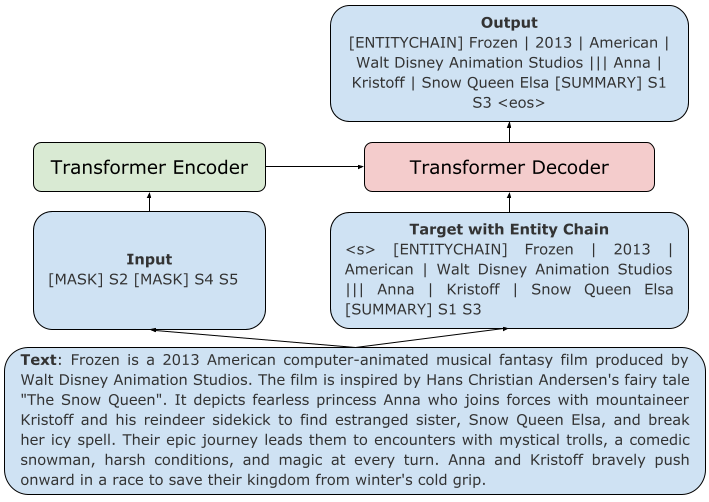
Pre-trained transformer-based sequence-to-sequence models have become the go-to solution for many text generation tasks, including summarization. However, the results produced by these models tend to contain significant issues such as hallucinations and irrelevant passages. One solution to mitigate these problems is to incorporate better content planning in neural summarization. We propose to use entity chains (i.e., chains of entities mentioned in the summary) to better plan and ground the generation of abstractive summaries. In particular, we augment the target by prepending it with its entity chain. We experimented with both pre-training and finetuning with this content planning objective. When evaluated on CNN/DailyMail, SAMSum and XSum, models trained with this objective improved on entity correctness and summary conciseness, and achieved state-of-the-art performance on ROUGE for SAMSum and XSum.
翻译:培训前的基于变压器的顺序到顺序模型已成为许多文本生成任务(包括总结)的通向解决方案,但是,这些模型产生的结果往往含有幻觉和不相关段落等重要问题。缓解这些问题的一个解决办法是将更好的内容规划纳入神经总结中。我们提议利用实体链(即摘要中提到的实体链链)更好地规划和开始生成抽象摘要。我们特别通过将目标与实体链一起设定来扩大目标。我们试验了培训前和对内容规划目标的微调。在对CNN/DailyMail、SAMSum和XSum进行评价时,将经过培训的模型改进为实体的正确性和简洁性,并在ROUGE上为SAMSum和XSum实现最先进的业绩。