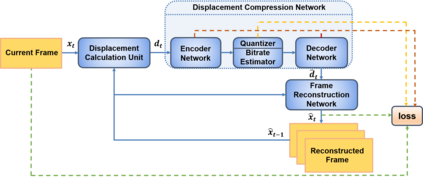
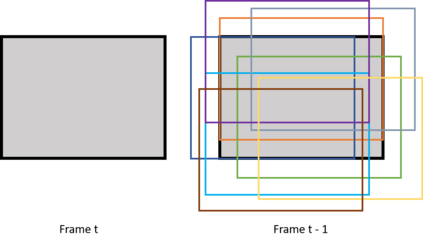
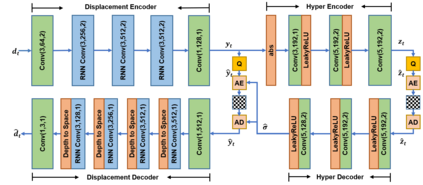
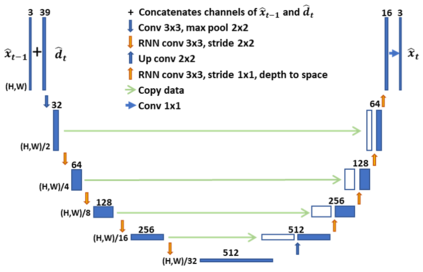
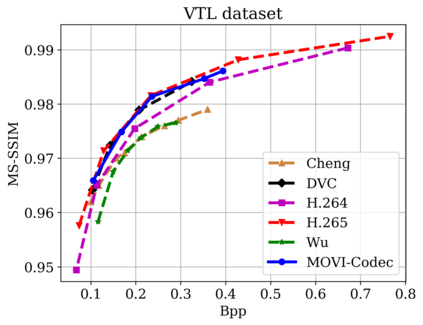
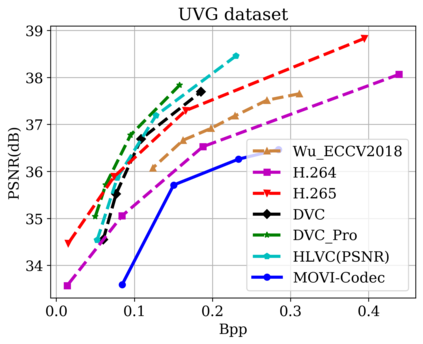
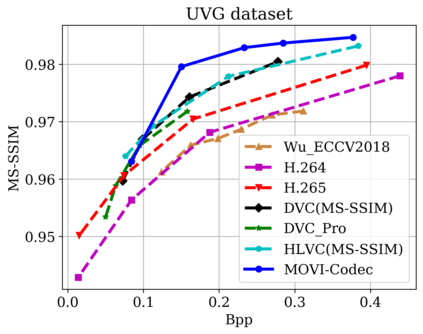
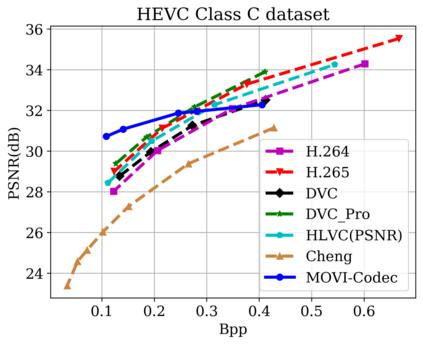
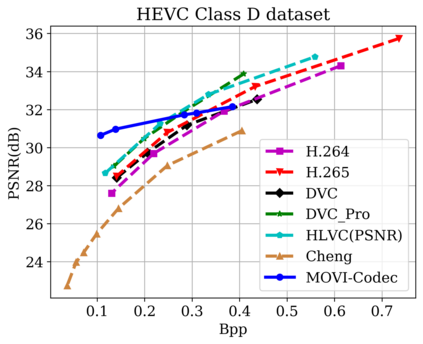
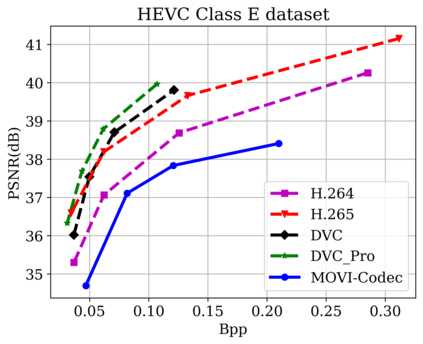
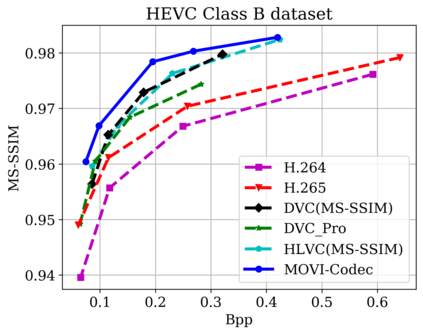
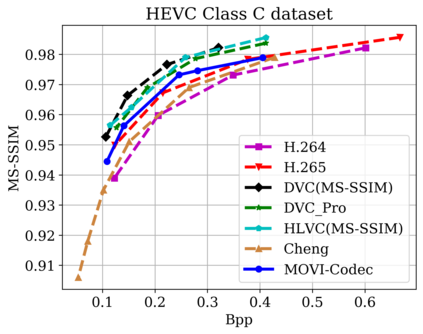
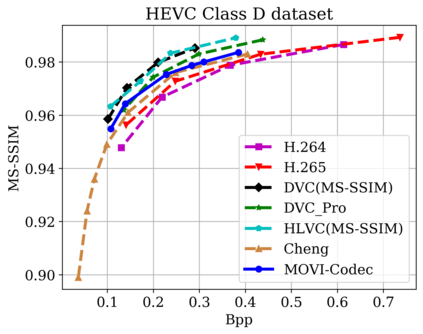
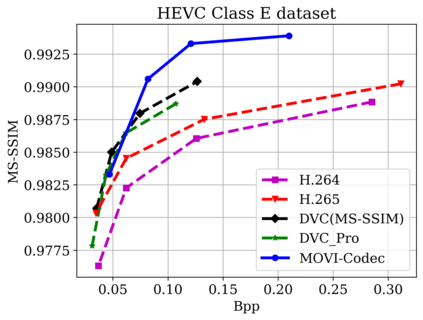
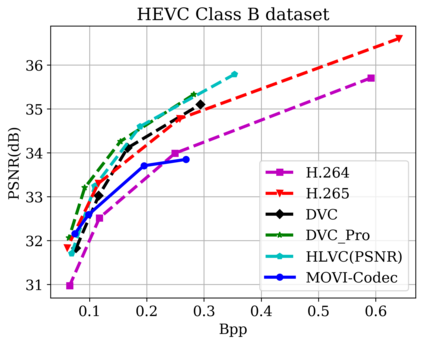
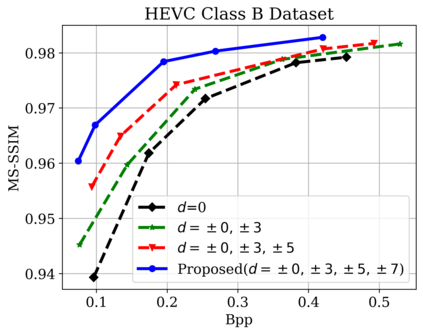
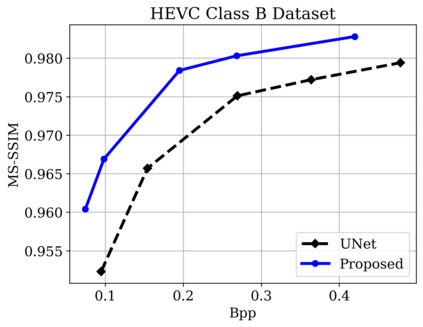
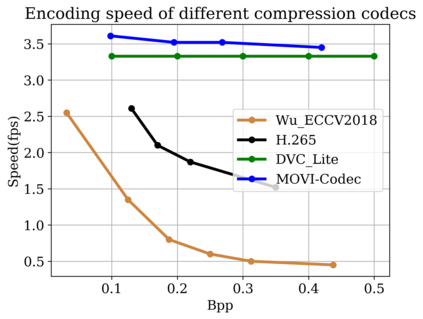
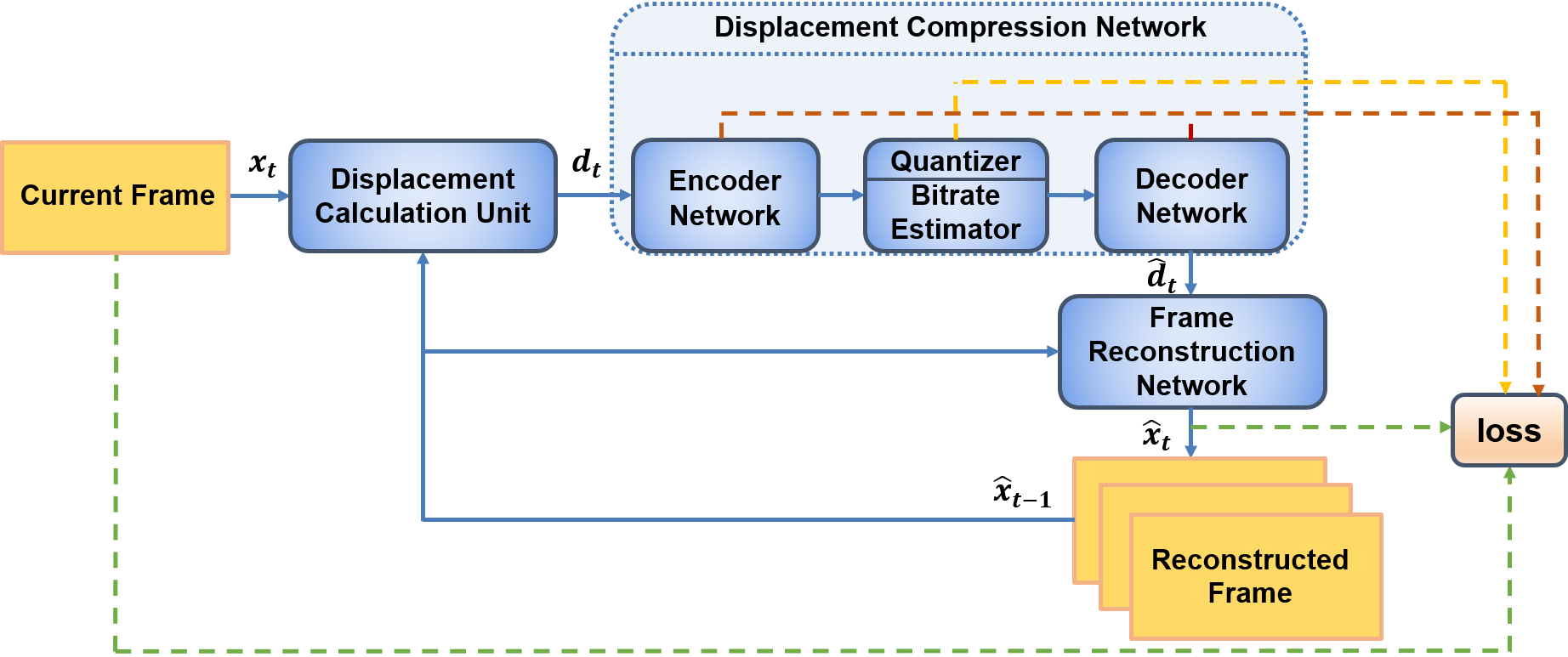
In this paper, we propose a new deep learning video compression architecture that does not require motion estimation, which is the most expensive element of modern hybrid video compression codecs like H.264 and HEVC. Our framework exploits the regularities inherent to video motion, which we capture by using displaced frame differences as video representations to train the neural network. In addition, we propose a new space-time reconstruction network based on both an LSTM model and a UNet model, which we call LSTM-UNet. The combined network is able to efficiently capture both temporal and spatial video information, making it highly amenable for our purposes. The new video compression framework has three components: a Displacement Calculation Unit (DCU), a Displacement Compression Network (DCN), and a Frame Reconstruction Network (FRN), all of which are jointly optimized against a single perceptual loss function. The DCU removes the need for motion estimation found in hybrid codecs, and is less expensive. In the DCN, an RNN-based network is utilized to compress displaced frame differences as well as retain temporal information between frames. The LSTM-UNet is used in the FRN to learn space time differential representations of videos. Our experimental results show that our compression model, which we call the MOtionless VIdeo Codec (MOVI-Codec), learns how to efficiently compress videos without computing motion. Our experiments show that MOVI-Codec outperforms the video coding standard H.264 and exceeds the performance of the modern global standard HEVC codec as measured by MS-SSIM, especially on higher resolution videos.
翻译:在本文中,我们提出一个新的不要求运动估计的深层次学习视频压缩结构,这是H.264和HEVC等现代混合视频压缩代码中最昂贵的元素。我们的框架利用了视频运动固有的规律性,我们用离位框架差异作为视频演示来拍摄,以培训神经网络。此外,我们提议建立一个基于LSTM模型和UNet模型的新的时空重建网络,我们称之为LSTM-UNet。联合网络能够有效捕捉时间和空间视频信息,使其高度适合我们的目的。新的视频压缩框架有三个组成部分:现代视频调整股(DCU)、流离失所压缩网络(DCN)和框架重建网络(FRN),所有这些都是用移动框架差异框架来作为视频展示的。 DCUC取消了在混合代码中发现的运动估计需要,而且成本较低。在DCN中,基于RNN的网络被用来压缩时间框架的差异,并保留两个框架之间的时间信息。新的视频压缩框架是一个现代的LSTM-UNT(DU)、迁移网络(DIS-Degrade Conde Redual Reduction)的模型显示我们的软体演示结果,特别用于我们的SIM-CEROdealdemode。