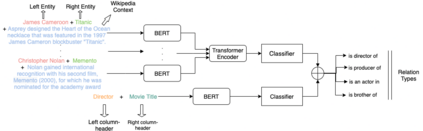
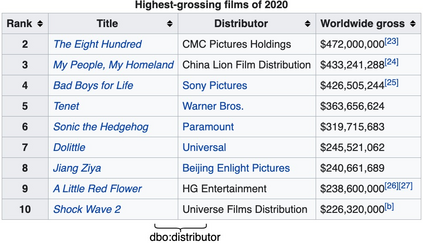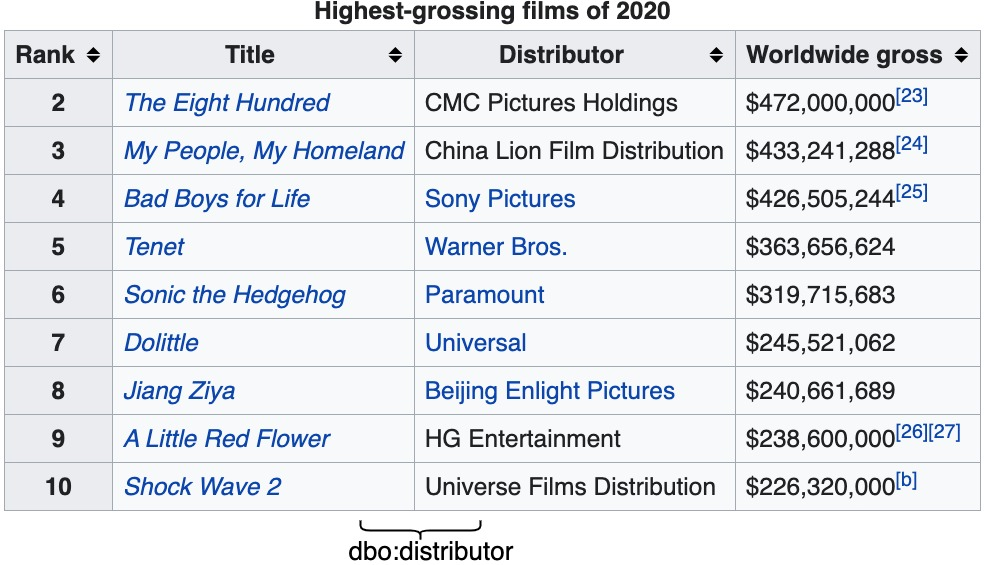Relation Extraction (RE) from tables is the task of identifying relations between pairs of columns of a table. Generally, RE models for this task require labelled tables for training. These labelled tables can also be generated artificially from a Knowledge Graph (KG), which makes the cost to acquire them much lower in comparison to manual annotations. However, unlike real tables, these synthetic tables lack associated metadata, such as, column-headers, captions, etc; this is because synthetic tables are created out of KGs that do not store such metadata. Meanwhile, previous works have shown that metadata is important for accurate RE from tables. To address this issue, we propose methods to artificially create some of this metadata for synthetic tables. Afterward, we experiment with a BERT-based model, in line with recently published works, that takes as input a combination of proposed artificial metadata and table content. Our empirical results show that this leads to an improvement of 9\%-45\% in F1 score, in absolute terms, over 2 tabular datasets.
翻译:从表格中提取关系(RE)是确定表格各列之间关系的任务。一般来说,这一任务的RE模型要求有标签的培训表格。这些标签的表格也可以由“知识图表”(KG)人工生成,该图使得获得这些表格的成本比手动说明要低得多。然而,与实际表格不同,这些合成表格缺乏相关的元数据,如列标题、标题等;这是因为合成表格是由不存储这类元数据的KG制成的。同时,以往的工作表明,元数据对于表格中准确的RE很重要。为了解决这一问题,我们建议了人为创建合成表格中的某些元数据的方法。之后,我们根据最近出版的著作,试验以BERT为基础的模型,该模型综合了拟议的人工元数据和表格内容。我们的经验结果表明,这导致F1分的9 ⁇ -45 ⁇ 的绝对值改进了2个表格数据集。