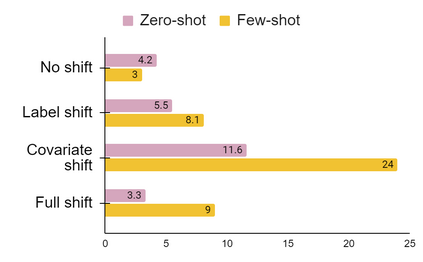
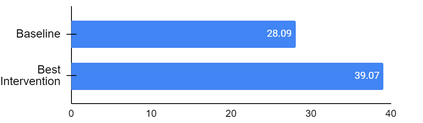
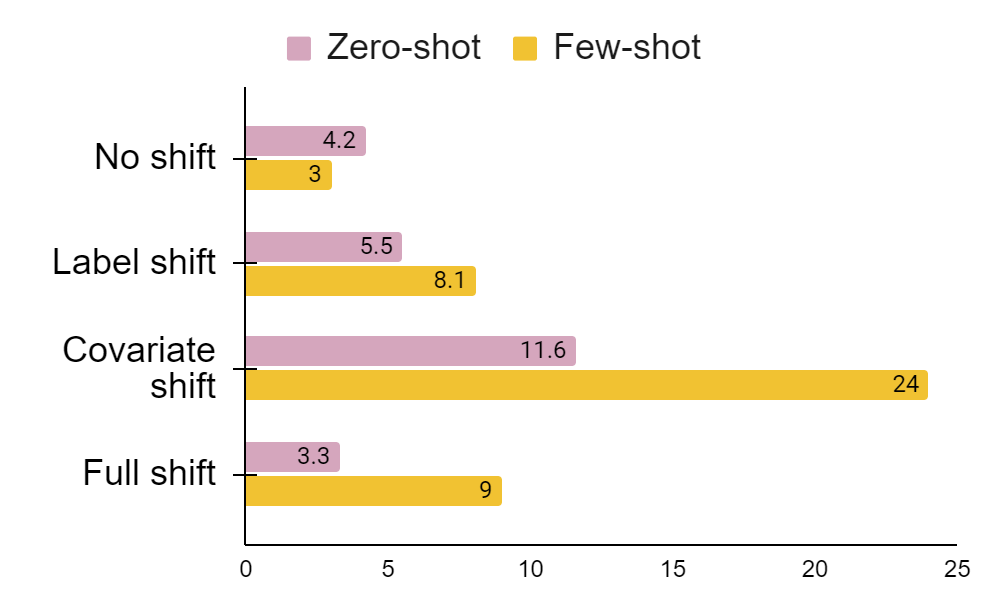
Recent advances in open-domain question answering (ODQA) have demonstrated impressive accuracy on standard Wikipedia style benchmarks. However, it is less clear how robust these models are and how well they perform when applied to real-world applications in drastically different domains. While there has been some work investigating how well ODQA models perform when tested for out-of-domain (OOD) generalization, these studies have been conducted only under conservative shifts in data distribution and typically focus on a single component (ie. retrieval) rather than an end-to-end system. In response, we propose a more realistic and challenging domain shift evaluation setting and, through extensive experiments, study end-to-end model performance. We find that not only do models fail to generalize, but high retrieval scores often still yield poor answer prediction accuracy. We then categorize different types of shifts and propose techniques that, when presented with a new dataset, predict if intervention methods are likely to be successful. Finally, using insights from this analysis, we propose and evaluate several intervention methods which improve end-to-end answer F1 score by up to 24 points.
翻译:开放域问题解答(ODQA)最近的进展在标准维基百科风格基准方面显示出令人印象深刻的准确性。然而,这些模型是否可靠,在应用到现实世界应用程序时在截然不同的不同领域表现如何,都不太清楚。虽然有些工作调查了ODQA模型在外域(OOOD)一般化测试时效果如何,但这些研究只是在数据分配的保守变化下进行的,通常侧重于单一部分(ie. recreit)而不是端对端系统。我们提出一个更现实和更具挑战性的域间转移评价设置,并通过广泛的实验,研究端对端模型性能。我们发现,不仅模型不普遍化,而且高检索分数往往导致不准确的预测。我们随后对不同类型的转移进行分类,并提出技术,在采用新的数据集时,预测干预方法是否可能成功。最后,我们利用这一分析的洞察结果,提出并评价若干干预方法,将F1端对F1的回答评分提高至24点。