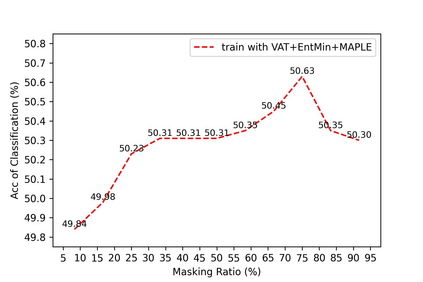
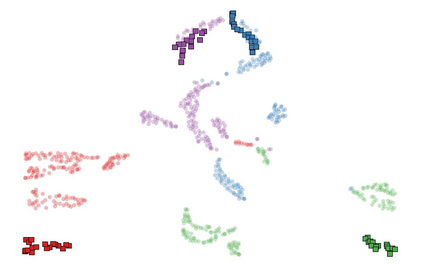
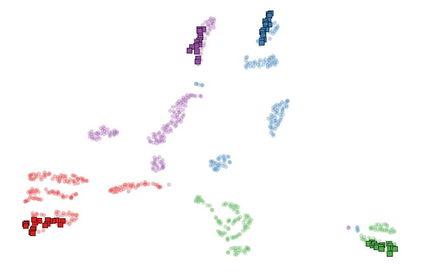
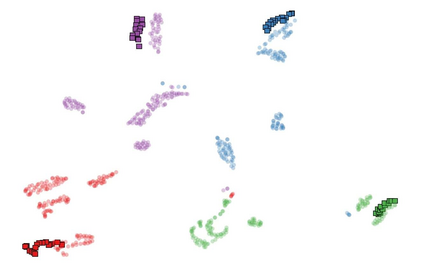
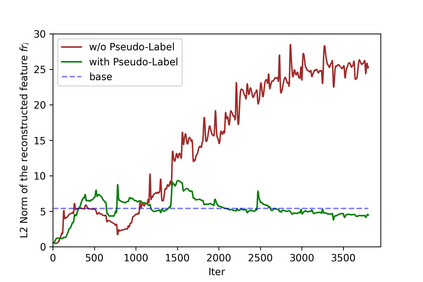
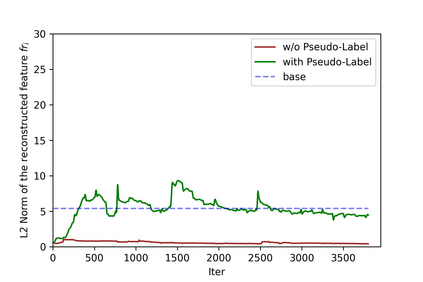
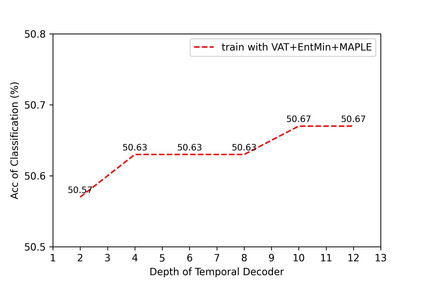
Recognizing human actions from point cloud videos has attracted tremendous attention from both academia and industry due to its wide applications like automatic driving, robotics, and so on. However, current methods for point cloud action recognition usually require a huge amount of data with manual annotations and a complex backbone network with high computation costs, which makes it impractical for real-world applications. Therefore, this paper considers the task of semi-supervised point cloud action recognition. We propose a Masked Pseudo-Labeling autoEncoder (\textbf{MAPLE}) framework to learn effective representations with much fewer annotations for point cloud action recognition. In particular, we design a novel and efficient \textbf{De}coupled \textbf{s}patial-\textbf{t}emporal Trans\textbf{Former} (\textbf{DestFormer}) as the backbone of MAPLE. In DestFormer, the spatial and temporal dimensions of the 4D point cloud videos are decoupled to achieve efficient self-attention for learning both long-term and short-term features. Moreover, to learn discriminative features from fewer annotations, we design a masked pseudo-labeling autoencoder structure to guide the DestFormer to reconstruct features of masked frames from the available frames. More importantly, for unlabeled data, we exploit the pseudo-labels from the classification head as the supervision signal for the reconstruction of features from the masked frames. Finally, comprehensive experiments demonstrate that MAPLE achieves superior results on three public benchmarks and outperforms the state-of-the-art method by 8.08\% accuracy on the MSR-Action3D dataset.
翻译:从点云视频中确认人类行动已经引起学术界和行业的极大关注,因为其应用范围很广,例如自动驱动、机器人等。然而,当前点云动作识别方法通常需要大量带有手动说明和计算成本高的复杂主干网的数据,这使得对现实世界应用程序来说不切实际。因此,本文认为半监督点云动作识别任务。我们提议了一个蒙蔽的 Pseudo-Labeing AutoEncoder (\ textbf{MAPLE}) 框架,以学习有效的表达方式,而点云动作识别的注释要少得多。特别是,我们设计了一个新的和高效的全面的点云动作识别方法。我们设计了一个新颖的和高效的全面的显示,从长期和短期的Drupplebf{Textbf{t} 和 Former} (\ textbff{Destff{Destfrormer} ) 将半监督点云雾化的显示为MAMELLELE的基底。我们从长期和短期的模型的模拟的模型,我们从现在的模型到现在的模拟的模型,从一个分析的模型的模型的模型的模型的模型, 和现在的模型的模型, 和现在的模型, 从一个分析的模型的模型的模型的模型的模型的模型, 和现在的模型的模型的模型。