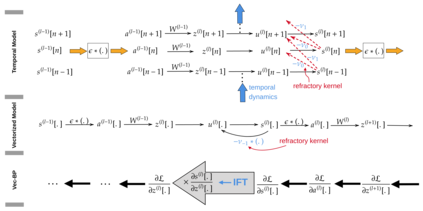
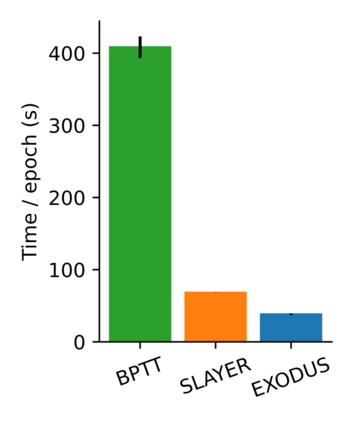
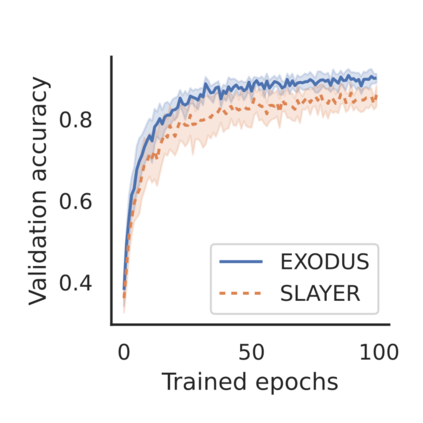
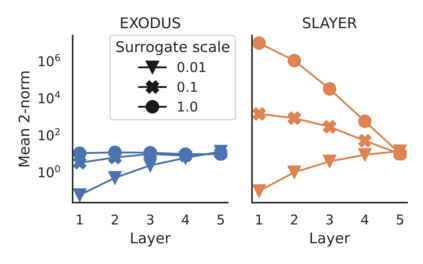
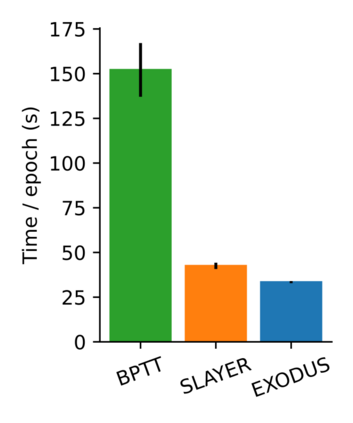
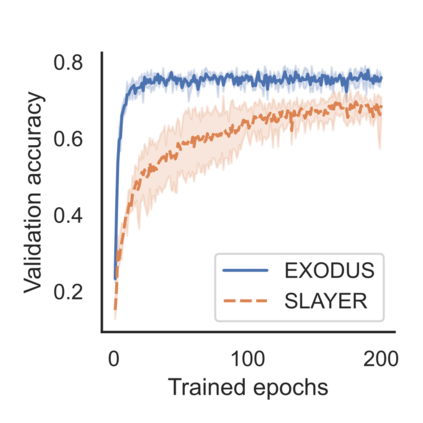
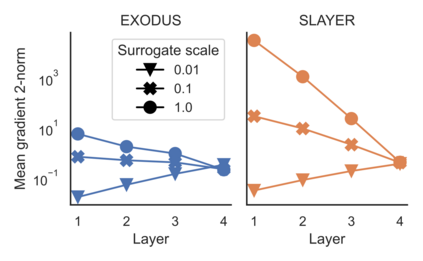
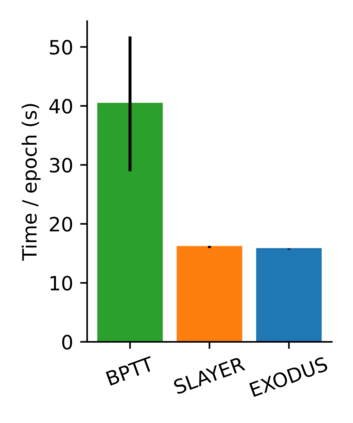
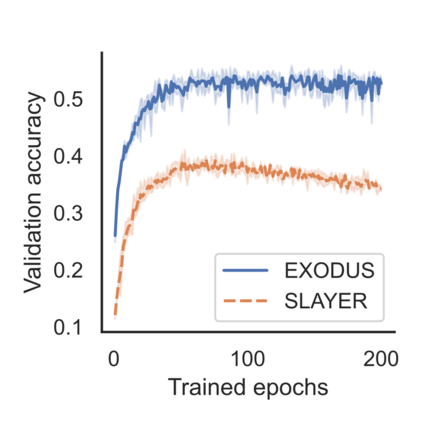
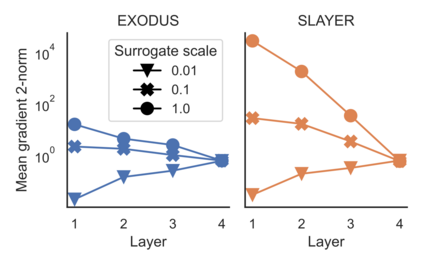
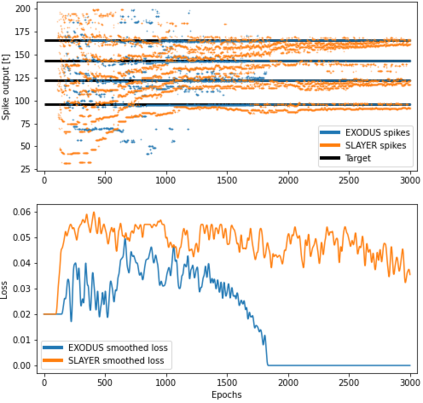
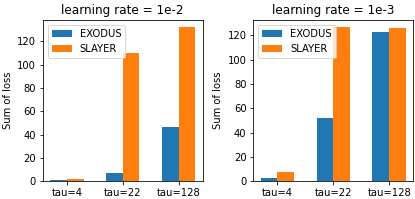
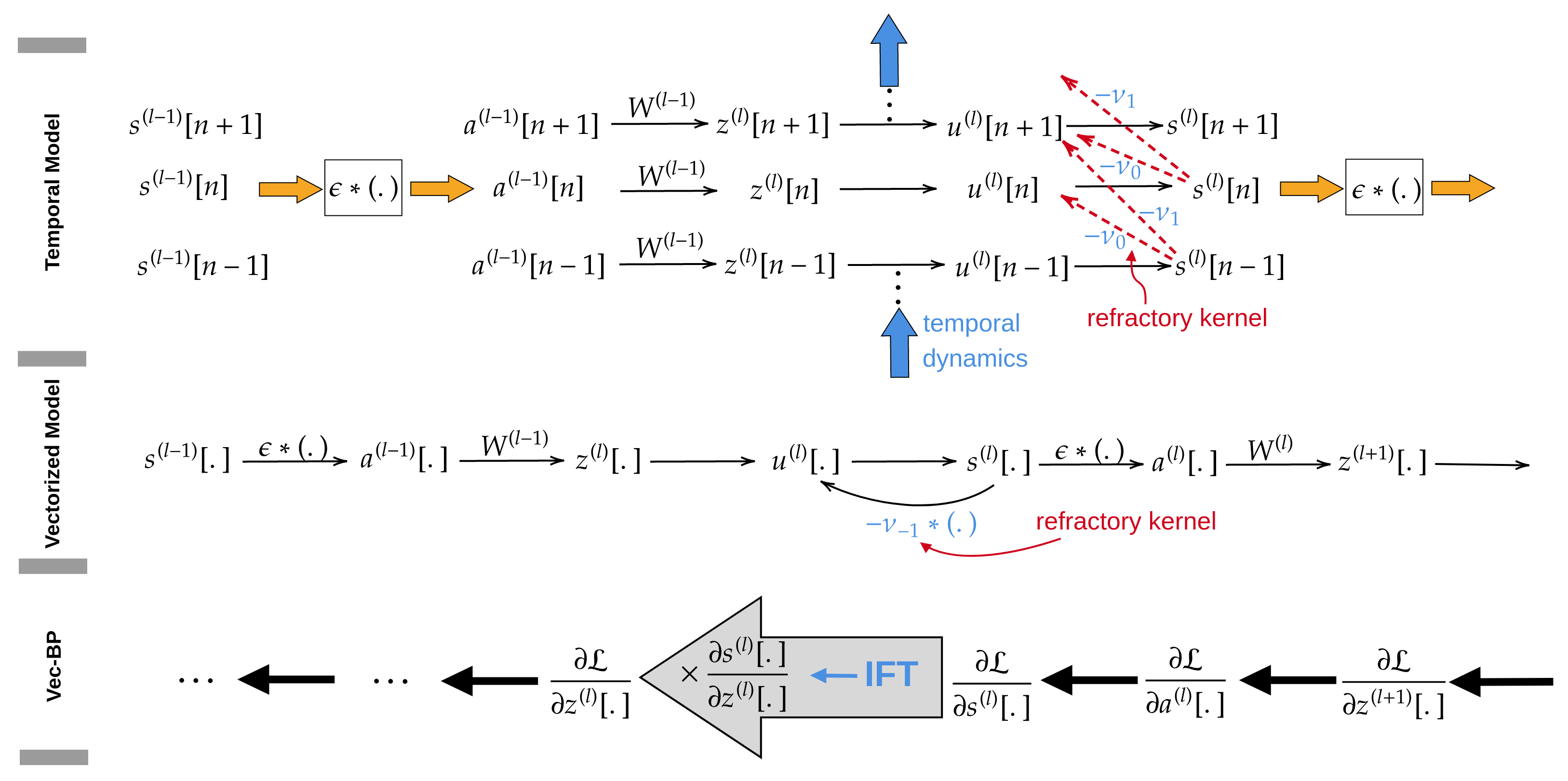
Spiking Neural Networks (SNNs) are gaining significant traction in machine learning tasks where energy-efficiency is of utmost importance. Training such networks using the state-of-the-art back-propagation through time (BPTT) is, however, very time-consuming. Previous work by Shrestha and Orchard [2018] employs an efficient GPU-accelerated back-propagation algorithm called SLAYER, which speeds up training considerably. SLAYER, however, does not take into account the neuron reset mechanism while computing the gradients, which we argue to be the source of numerical instability. To counteract this, SLAYER introduces a gradient scale hyperparameter across layers, which needs manual tuning. In this paper, (i) we modify SLAYER and design an algorithm called EXODUS, that accounts for the neuron reset mechanism and applies the Implicit Function Theorem (IFT) to calculate the correct gradients (equivalent to those computed by BPTT), (ii) we eliminate the need for ad-hoc scaling of gradients, thus, reducing the training complexity tremendously, (iii) we demonstrate, via computer simulations, that EXODUS is numerically stable and achieves a comparable or better performance than SLAYER especially in various tasks with SNNs that rely on temporal features. Our code is available at https://github.com/synsense/sinabs-exodus.
翻译:Spiking神经网络(SNNS)在能源效率极为重要的机器学习任务中正在获得显著的牵引力。然而,利用最先进的后反向分析时间(BBTT)对此类网络进行培训非常耗时。 Shrestha和Orchard [2018] 先前的工作使用了高效的GPU-加速后向分析算法,称为SLAYER,该算法大大加快了培训。 然而,SLAYER在计算梯度时没有考虑到神经重置机制,而我们认为这是数字不稳定的根源。为了抵消这一点,SLAYER在各层中引入了梯度超参数,这需要手工调整。在本文中,(i)我们修改SLAYER并设计了一个称为EXODUS的算法,该算出神经重置机制,并应用隐性函数理论来计算正确的梯度(相当于BPTT的算法),(ii)我们在计算梯度时没有考虑到神经重重重的重置机制,因此,我们不需要在梯度上进行梯度的缩缩缩缩,因此需要跨度,在各层次上设置上,从而降低SRAY(SUR三)在模拟中可以进行精确的计算。