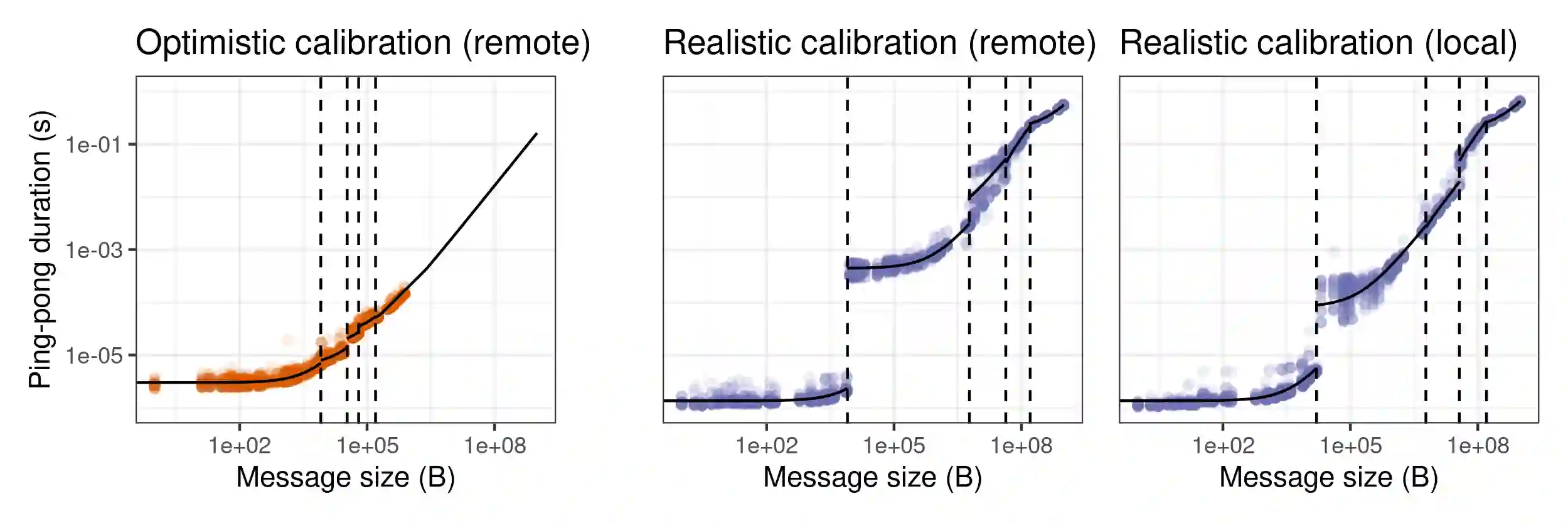
Finely tuning MPI applications and understanding the influence of keyparameters (number of processes, granularity, collective operationalgorithms, virtual topology, and process placement) is critical toobtain good performance on supercomputers. With the high consumptionof running applications at scale, doing so solely to optimize theirperformance is particularly costly. Havinginexpensive but faithful predictions of expected performance could bea great help for researchers and system administrators. Themethodology we propose decouples the complexity of the platform, whichis captured through statistical models of the performance of its maincomponents (MPI communications, BLAS operations), from the complexityof adaptive applications by emulating the application and skippingregular non-MPI parts of the code. We demonstrate the capability of our method with High-PerformanceLinpack (HPL), the benchmark used to rank supercomputers in theTOP500, which requires careful tuning. We briefly present (1) how theopen-source version of HPL can be slightly modified to allow a fastemulation on a single commodity server at the scale of asupercomputer. Then we present (2) an extensive (in)validation studythat compares simulation with real experiments and demonstrates our ability to predict theperformance of HPL within a few percent consistently. This study allows us toidentify the main modeling pitfalls (e.g., spatial and temporal nodevariability or network heterogeneity and irregular behavior) that needto be considered. Last, we show (3) how our ``surrogate'' allowsstudying several subtle HPL parameter optimization problems whileaccounting for uncertainty on the platform.
翻译:精细调整 MPI 应用程序并理解关键参数( 过程数量、 颗粒性、 集体操作性操作性、 虚拟地形和进程布局) 的影响,对于在超级计算机上取得良好性能至关重要。 随着运行应用程序在规模上消耗量高, 仅用于优化其性能的成本特别高。 对预期性能的不昂贵但忠实的预测可能对研究人员和系统管理员大有帮助。 主题学我们提议解析平台的复杂性, 平台通过主要部件( MPI 通信、 BLAS 操作) 的性能统计模型, 从适应性应用的复杂性能中采集, 通过模拟应用和跳过常规的非MPI 代码部分。 我们用高性能Linpack (HPL) 展示了我们的方法能力, 用于在TOP 500 中将超级计算机排位的基准需要仔细调整。 我们简单展示 (1) 如何对 HPLLL 的公开性能版本进行微小的修改, 以便能够在超级计算机规模的单个商品服务器上快速模拟( ), 然后让我们的精细化的精细的精细的精细的精细的精细的轨性实验。