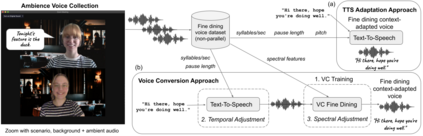
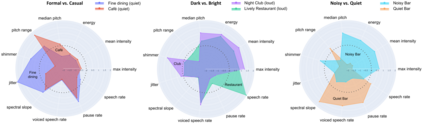
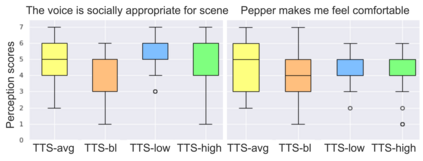
Adapting one's voice to different ambient environments and social interactions is required for human social interaction. In robotics, the ability to recognize speech in noisy and quiet environments has received significant attention, but considering ambient cues in the production of social speech features has been little explored. Our research aims to modify a robot's speech to maximize acceptability in various social and acoustic contexts, starting with a use case for service robots in varying restaurants. We created an original dataset collected over Zoom with participants conversing in scripted and unscripted tasks given 7 different ambient sounds and background images. Voice conversion methods, in addition to altered Text-to-Speech that matched ambient specific data, were used for speech synthesis tasks. We conducted a subjective perception study that showed humans prefer synthetic speech that matches ambience and social context, ultimately preferring more human-like voices. This work provides three solutions to ambient and socially appropriate synthetic voices: (1) a novel protocol to collect real contextual audio voice data, (2) tools and directions to manipulate robot speech for appropriate social and ambient specific interactions, and (3) insight into voice conversion's role in flexibly altering robot speech to match different ambient environments.
翻译:人类社会互动需要使一个人的声音适应不同的环境环境和社会互动。 在机器人方面,在吵闹和安静环境中识别语言的能力受到极大关注,但在制作社会演讲特征时考虑环境信号的能力却很少得到探讨。我们的研究旨在修改机器人的演讲,以便在不同的社会和声学环境中最大限度地获得接受,首先从在不同餐馆服务机器人的使用情况开始。我们创建了在Zoom上收集的原始数据集,参与者在7种不同的环境声音和背景图像中对脚本和无指令任务进行交谈。语音转换方法,除了用于改变与环境特定数据相匹配的文字对语音外,还用于语言合成任务。我们进行了主观认知研究,显示人类更喜欢与矛盾和社会背景相匹配的合成语言,最终更喜欢人性的声音。这项工作为环境上和社会上合适的合成声音提供了三种解决方案:(1) 收集真实背景声音数据的新协议,(2) 用于操纵机器人语言以进行适当的社会和环境特定互动的工具和方向,(3) 深入了解声音转换在灵活改变机器人讲话中的角色,以适应不同的环境环境环境环境。