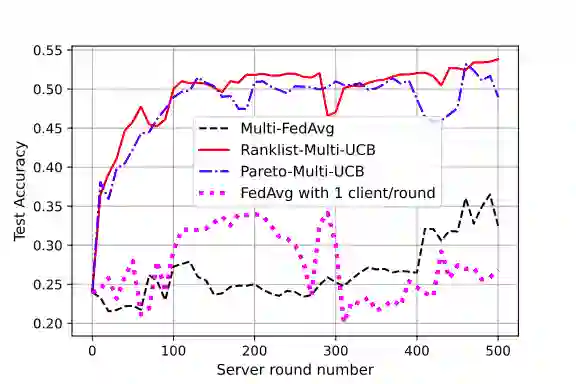
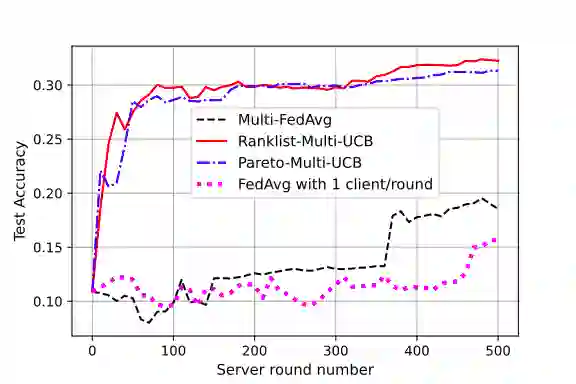
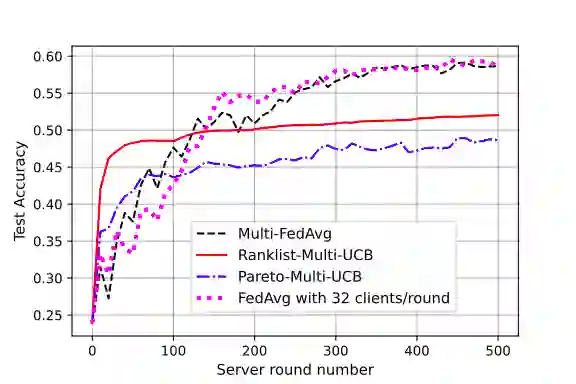
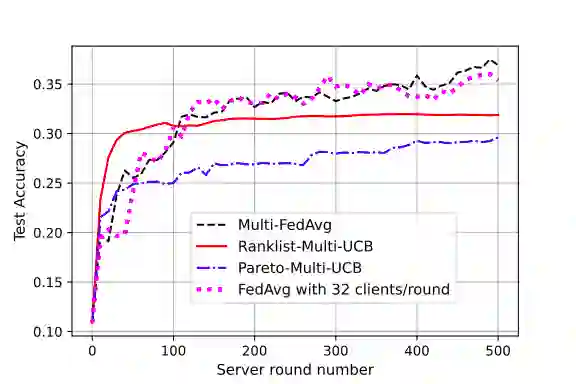
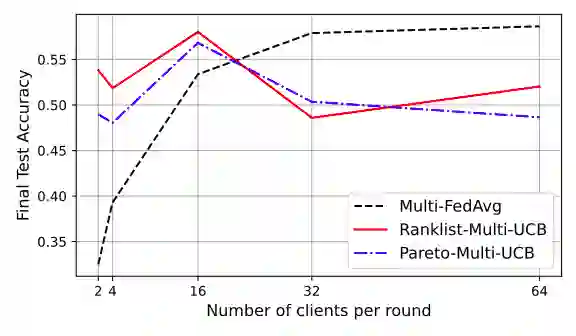
Federated learning is a form of distributed learning with the key challenge being the non-identically distributed nature of the data in the participating clients. In this paper, we extend federated learning to the setting where multiple unrelated models are trained simultaneously. Specifically, every client is able to train any one of M models at a time and the server maintains a model for each of the M models which is typically a suitably averaged version of the model computed by the clients. We propose multiple policies for assigning learning tasks to clients over time. In the first policy, we extend the widely studied FedAvg to multi-model learning by allotting models to clients in an i.i.d. stochastic manner. In addition, we propose two new policies for client selection in a multi-model federated setting which make decisions based on current local losses for each client-model pair. We compare the performance of the policies on tasks involving synthetic and real-world data and characterize the performance of the proposed policies. The key take-away from our work is that the proposed multi-model policies perform better or at least as good as single model training using FedAvg.
翻译:联邦学习是一种分布式学习形式,主要挑战在于参与客户中数据的非明显分布性质。在本文中,我们将联合学习推广到同时培训多个不相干模型的环境下。具体地说,每个客户都能够一次培训任何M型模型,服务器为每个M型模型都保留一个模型,该模型通常是客户计算模型的适当平均版本。我们提出了长期向客户分配学习任务的多种政策。在第一种政策中,我们把广泛研究的FedAvg推广到通过以i.d. 随机方式向客户分配模型的多模式学习。此外,我们提出两项新的政策,在多模式环境中选择客户,根据每对客户模式的当前当地损失作出决定。我们比较涉及合成数据和真实世界数据的任务的政策绩效,并描述拟议政策的业绩。我们的主要成果是,拟议的多模式政策以i.d.d. 随机方式向客户分配模型,从而更好或至少作为使用FedAvg的单一模式培训的好。