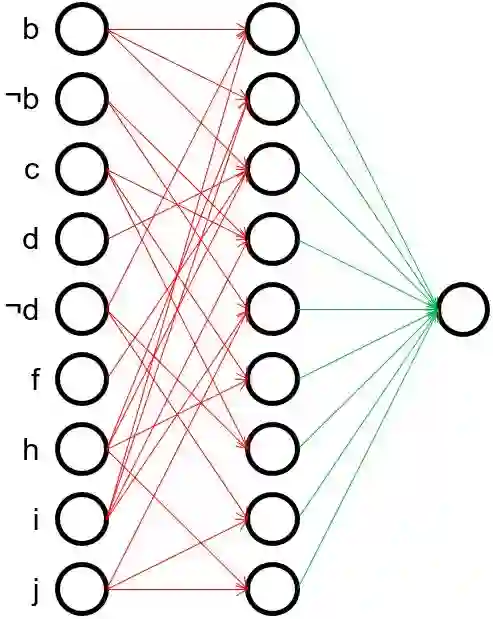
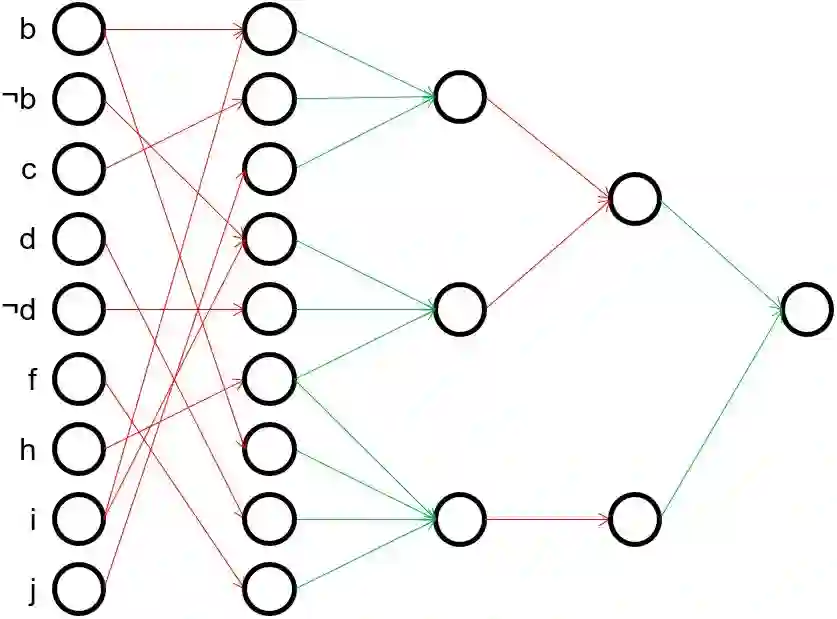
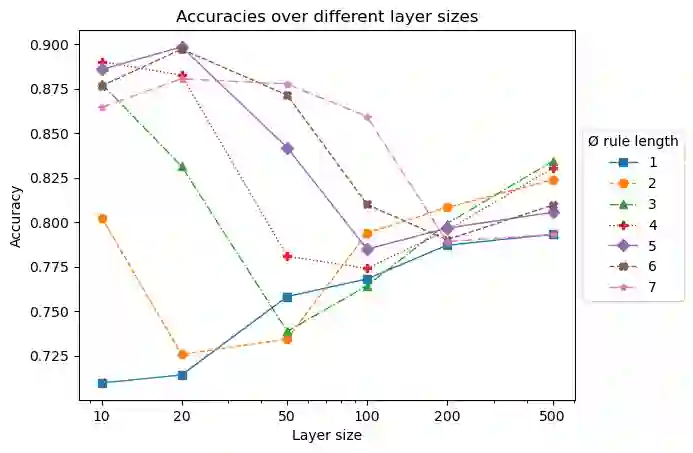
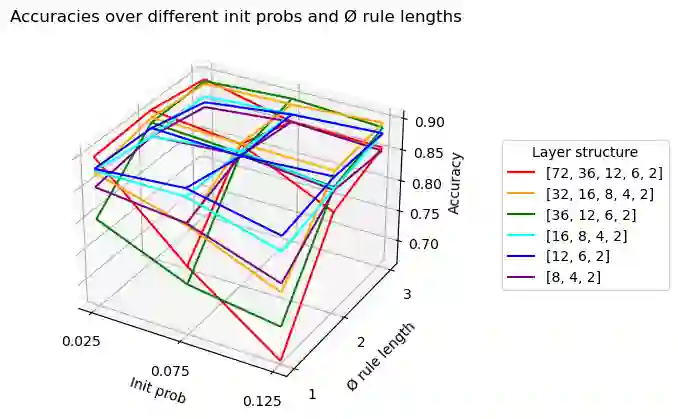
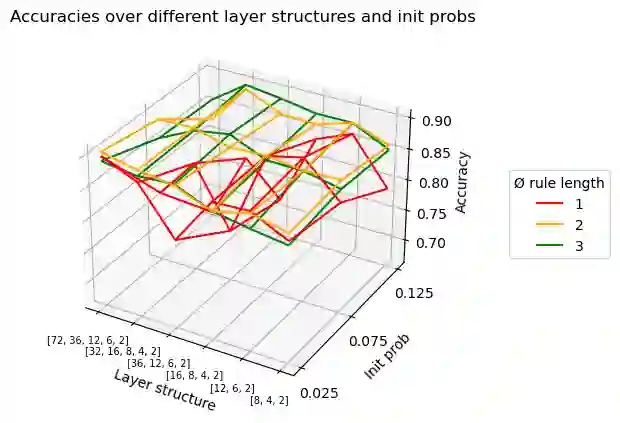
Inductive rule learning is arguably among the most traditional paradigms in machine learning. Although we have seen considerable progress over the years in learning rule-based theories, all state-of-the-art learners still learn descriptions that directly relate the input features to the target concept. In the simplest case, concept learning, this is a disjunctive normal form (DNF) description of the positive class. While it is clear that this is sufficient from a logical point of view because every logical expression can be reduced to an equivalent DNF expression, it could nevertheless be the case that more structured representations, which form deep theories by forming intermediate concepts, could be easier to learn, in very much the same way as deep neural networks are able to outperform shallow networks, even though the latter are also universal function approximators. In this paper, we empirically compare deep and shallow rule learning with a uniform general algorithm, which relies on greedy mini-batch based optimization. Our experiments on both artificial and real-world benchmark data indicate that deep rule networks outperform shallow networks.
翻译:引入规则的学习可以说是机器学习中最传统的范例之一。 尽管我们多年来在学习基于规则的理论方面取得了相当大的进步,但所有最先进的学习者仍然学会了直接将输入特征与目标概念直接联系起来的描述。 在最简单的例子中,概念学习,这是对正级的分解的正常形式。从逻辑角度看,这显然足够,因为每个逻辑表达方式都可以减到相当于DNF的表达方式,但是,可能出现这样的情况:通过形成中间概念形成深层次理论的更结构化的表达方式可能更容易学习,就像深层神经网络能够超越浅层网络一样,即使后者也是通用功能相似者。在本文中,我们从经验上将深度和浅度规则学习与依赖贪婪微量优化的通用算法进行比较。 我们在人工和真实世界基准数据方面的实验表明,深层规则网络超越浅端网络。