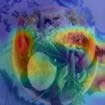
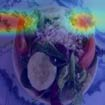
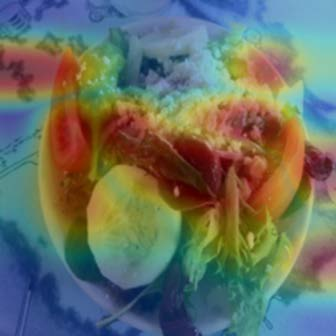
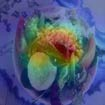
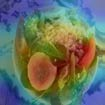
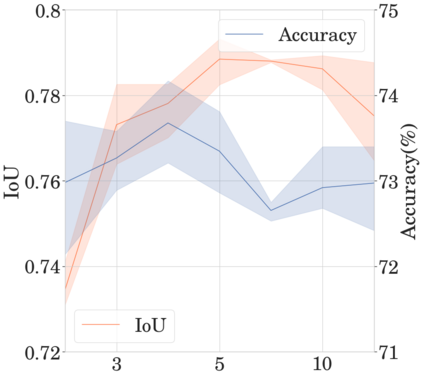
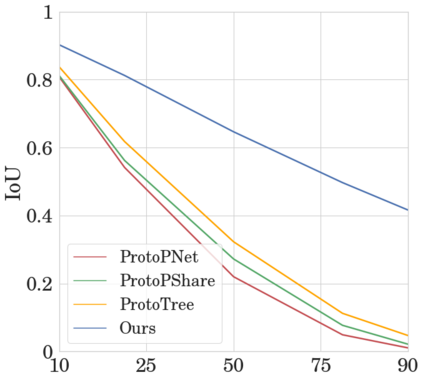
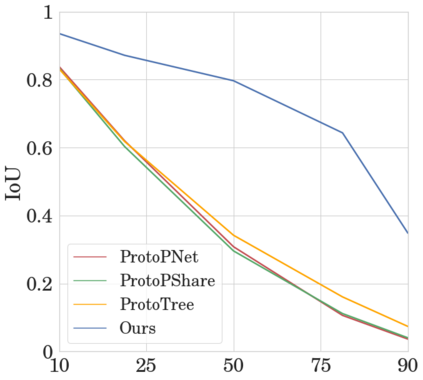
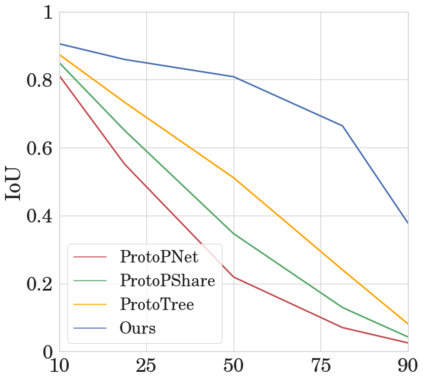
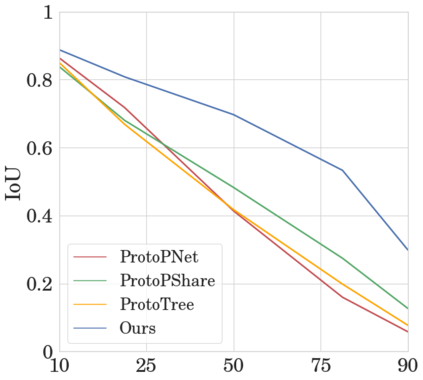
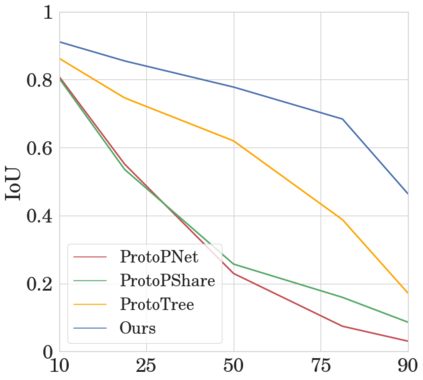
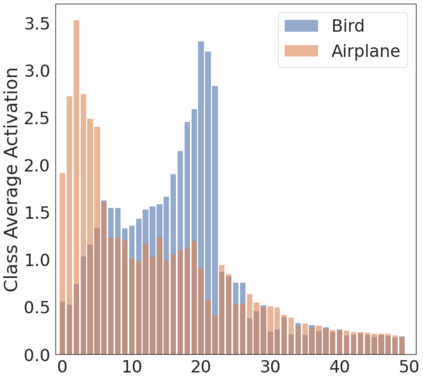
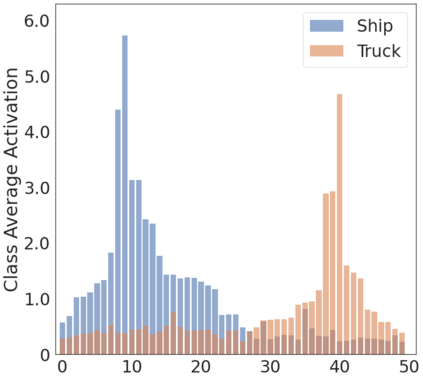
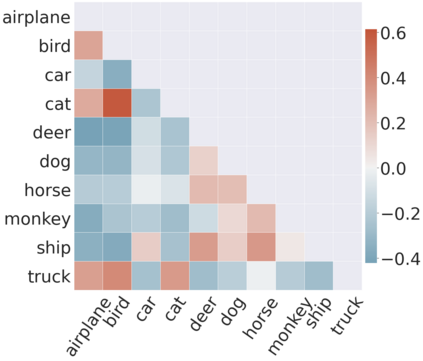
To interpret deep models' predictions, attention-based visual cues are widely used in addressing \textit{why} deep models make such predictions. Beyond that, the current research community becomes more interested in reasoning \textit{how} deep models make predictions, where some prototype-based methods employ interpretable representations with their corresponding visual cues to reveal the black-box mechanism of deep model behaviors. However, these pioneering attempts only either learn the category-specific prototypes and deteriorate their generalizing capacities, or demonstrate several illustrative examples without a quantitative evaluation of visual-based interpretability with further limitations on their practical usages. In this paper, we revisit the concept of visual words and propose the Learnable Visual Words (LVW) to interpret the model prediction behaviors with two novel modules: semantic visual words learning and dual fidelity preservation. The semantic visual words learning relaxes the category-specific constraint, enabling the general visual words shared across different categories. Beyond employing the visual words for prediction to align visual words with the base model, our dual fidelity preservation also includes the attention guided semantic alignment that encourages the learned visual words to focus on the same conceptual regions for prediction. Experiments on six visual benchmarks demonstrate the superior effectiveness of our proposed LVW in both accuracy and model interpretation over the state-of-the-art methods. Moreover, we elaborate on various in-depth analyses to further explore the learned visual words and the generalizability of our method for unseen categories.
翻译:为了解释深层次模型的预测,人们广泛使用基于关注的视觉提示来解释深层次模型的预测。此外,当前研究界对深层次模型的推理更加感兴趣,而一些基于原型的方法则使用其相应的视觉提示来进行解释,以揭示深层次模型行为的黑盒机制。然而,这些开创性尝试只是要么学习特定类别的原型,使其普遍化能力恶化,要么展示若干说明性实例,而不对基于视觉的可解释性进行定量评价,进一步限制其实际用途。在本文中,我们重新审视视觉文字的概念,并提议采用可理解的视觉文字(LVW)来解释模型预测行为,使用两个新颖的模块:语义视觉文字学习和双重忠诚保护。语义学文字学习放松了特定类别的限制,使不同类别之间共享的一般视觉文字得以恶化。除了使用视觉语言来预测视觉文字与基础模型保持一致,我们的双重忠诚保护还包括关注引导性文字的排列性调整,鼓励在一般的视觉分析中学习的视觉判断性语言,同时在一般的概念性分析中也展示了我们所学习的视觉判断性分析的视觉精确性。