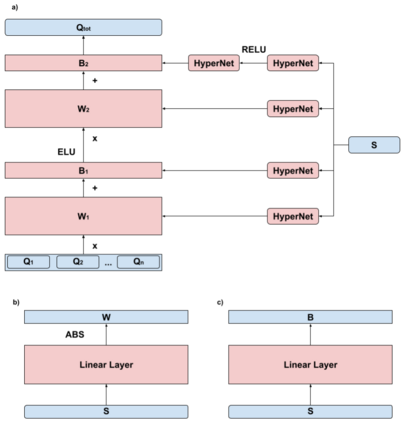
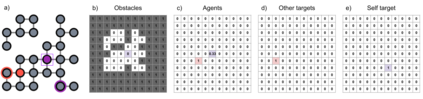
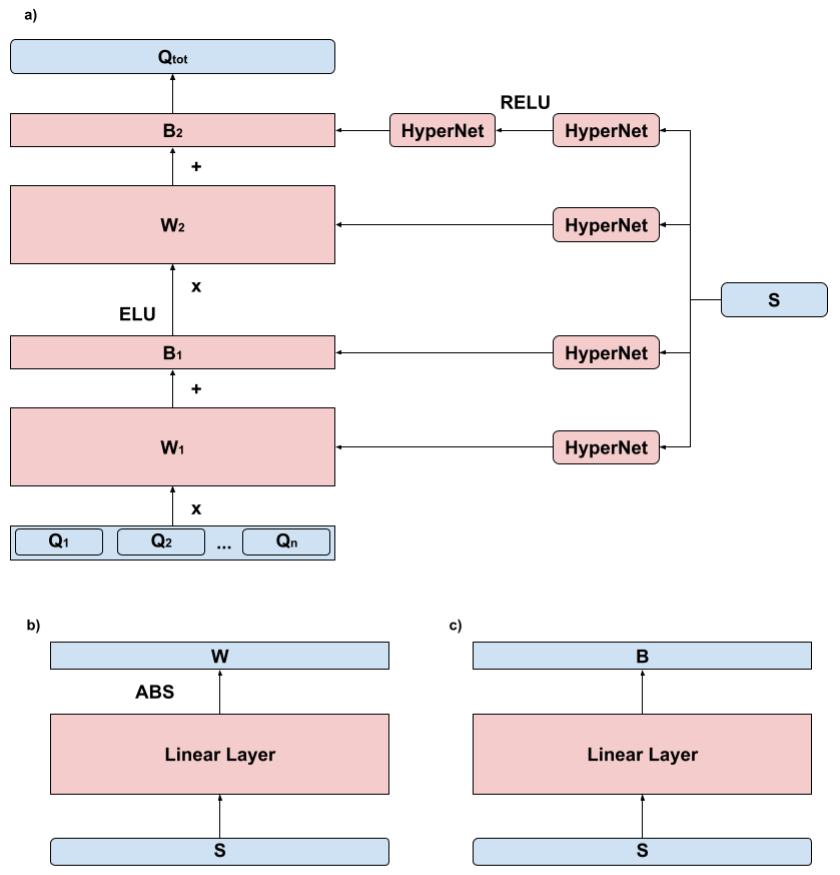
In this paper, we consider the problem of multi-agent navigation in partially observable grid environments. This problem is challenging for centralized planning approaches as they, typically, rely on the full knowledge of the environment. We suggest utilizing the reinforcement learning approach when the agents, first, learn the policies that map observations to actions and then follow these policies to reach their goals. To tackle the challenge associated with learning cooperative behavior, i.e. in many cases agents need to yield to each other to accomplish a mission, we use a mixing Q-network that complements learning individual policies. In the experimental evaluation, we show that such approach leads to plausible results and scales well to large number of agents.
翻译:在本文中,我们考虑了在部分可观测的电网环境中多试剂导航的问题。这个问题对集中规划方法具有挑战性,因为它们通常依赖对环境的充分了解。我们建议,当代理人首先学习将观测映射为行动的政策,然后遵循这些政策来实现其目标时,使用强化学习方法。为了应对与学习合作行为有关的挑战,即在许多情况下,代理人需要相互让步来完成使命,我们使用混合的Q-网络来补充学习个别政策。在实验性评估中,我们表明,这种方法可以产生可信的结果,并且对大量代理人来说,规模也很好。