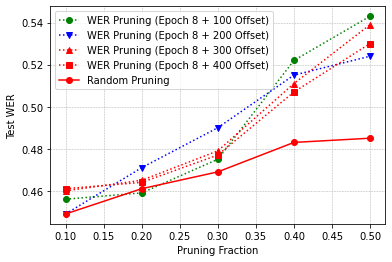
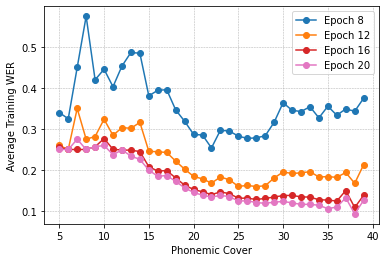
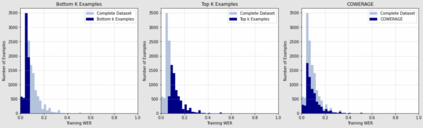
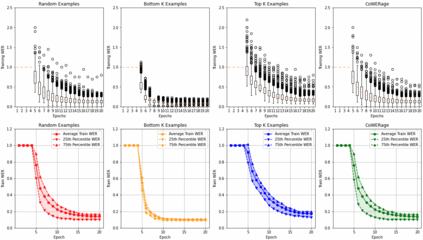
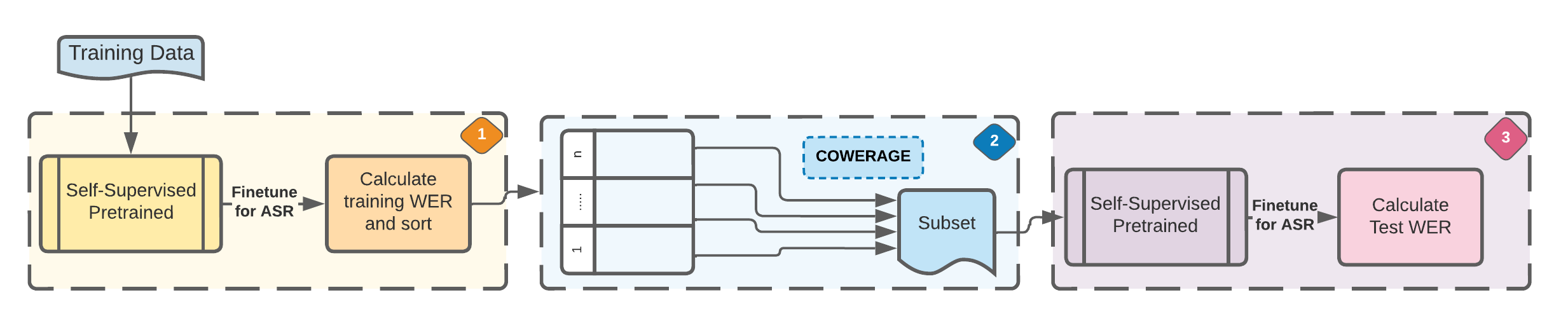
Self-supervised speech recognition models require considerable labeled training data for learning high-fidelity representations for Automatic Speech Recognition (ASR) which is computationally demanding and time-consuming, thereby hindering the usage of these models in resource-constrained environments. We consider the task of identifying an optimal subset of data to train self-supervised speech models for ASR. We make a surprising observation that the dataset pruning strategies used in vision tasks for sampling the most informative examples do not perform better than random subset selection on the task of fine-tuning self-supervised ASR. We then present the COWERAGE algorithm for better subset selection in self-supervised ASR, which is based on our finding that ensuring the coverage of examples based on training Word Error Rate (WER) in the early training epochs leads to better generalization performance. Extensive experiments on the wav2vec 2.0 model and TIMIT, Librispeech, and LJSpeech datasets show the effectiveness of COWERAGE, with up to 17% absolute WER improvement over existing dataset pruning methods and random sampling. We also demonstrate that the coverage of training instances in terms of WER ensures inclusion of phonemically diverse examples which leads to better test accuracy in self-supervised speech recognition models.
翻译:自我监督的语音识别模型需要大量有标签的培训数据,用于学习高度忠诚的自动语音识别(ASR)演示,这些数据在计算上既费时又费时,从而妨碍在资源紧张的环境中使用这些模型。我们考虑的任务是确定一个最佳数据子集,用于为ASR培训自监督的语音模型。我们令人惊讶地发现,用于抽样最丰富实例的愿景任务中所使用的数据集调整战略没有比在微调自监督的自动语音识别(ASR)任务中随机选择子集效果更好的。然后我们提出COWERAGE算法,以便在自我监督的ASR中更好地选择子集,从而妨碍在资源紧张的环境中使用这些模型。我们认为,确保早期培训中基于培训“WER”错误率(WER)的范例的涵盖范围能够提高通用性。关于WV2vec 2.0模型和TIMEXT、 Librispeech和LJSpeech数据集的广泛实验显示COWERAGEGE的功效,在现有的语音拼写方法的绝对WERSurview Passiming Exprendation Explication Expreving Explication Expreving Express Express exeration exeration Expressive exeration exactacts exact exacts exeration ex ex ex ex ex ex ex ex ex ex exual exual exuction sution suital 演示,在Weffective 中可以保证在Wectionive 中更好地进行更好的演示。