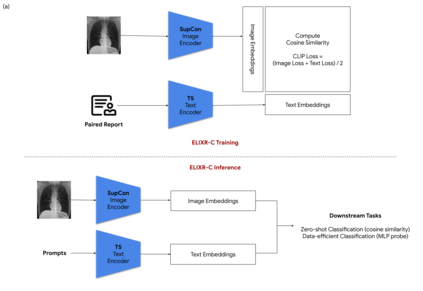
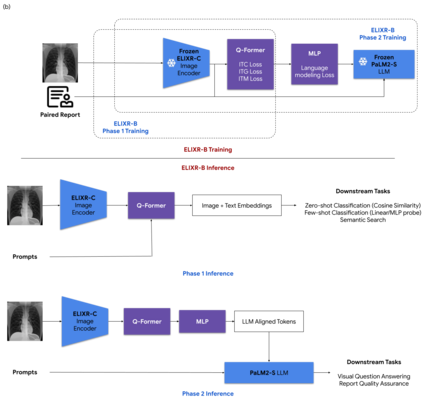
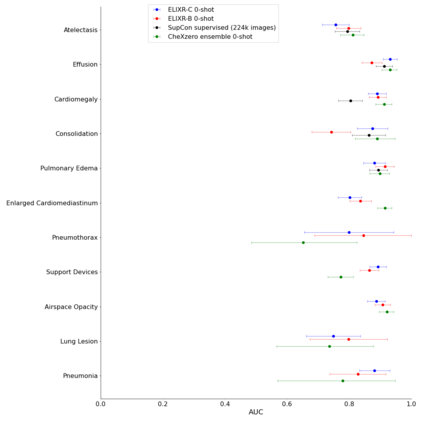
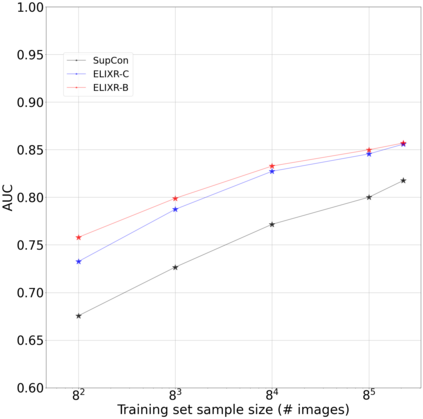
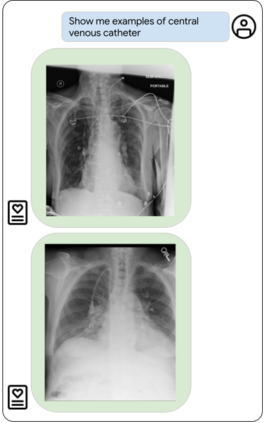
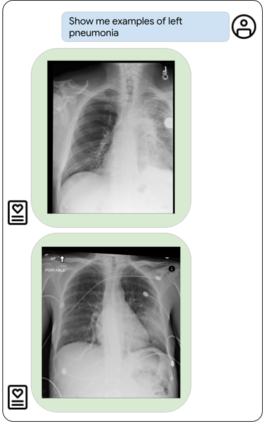
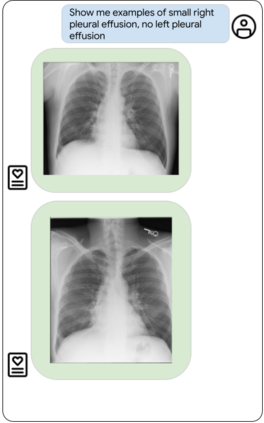
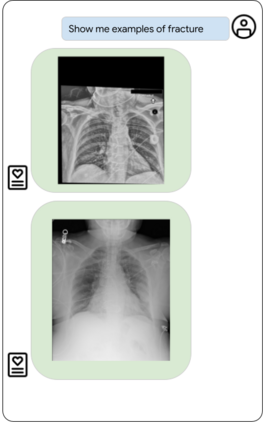
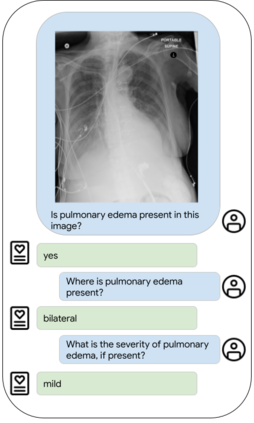
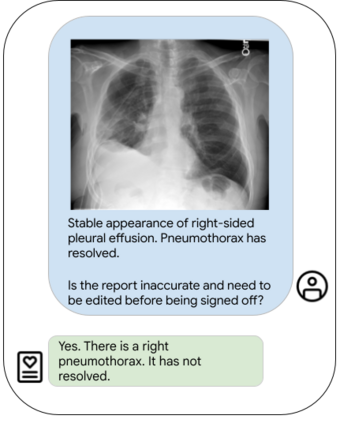
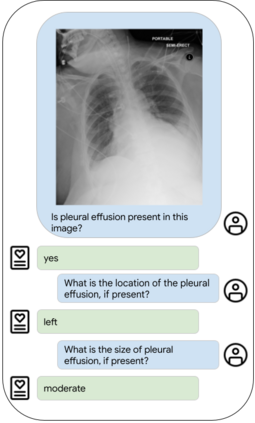
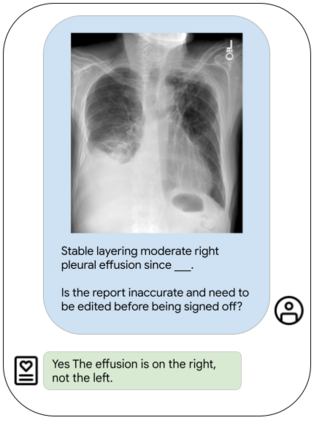
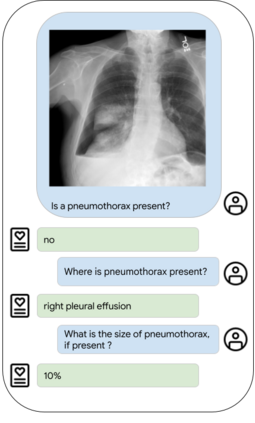
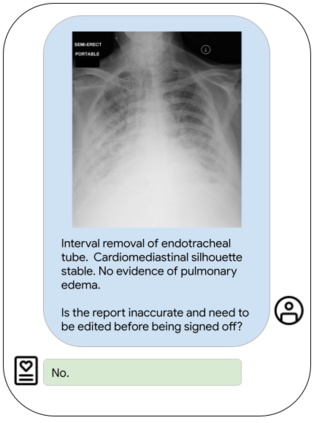
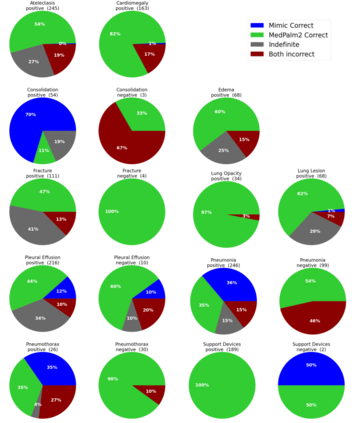
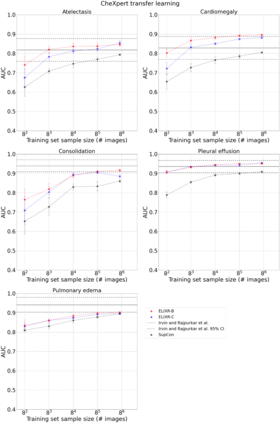
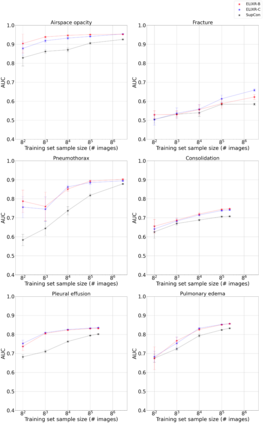
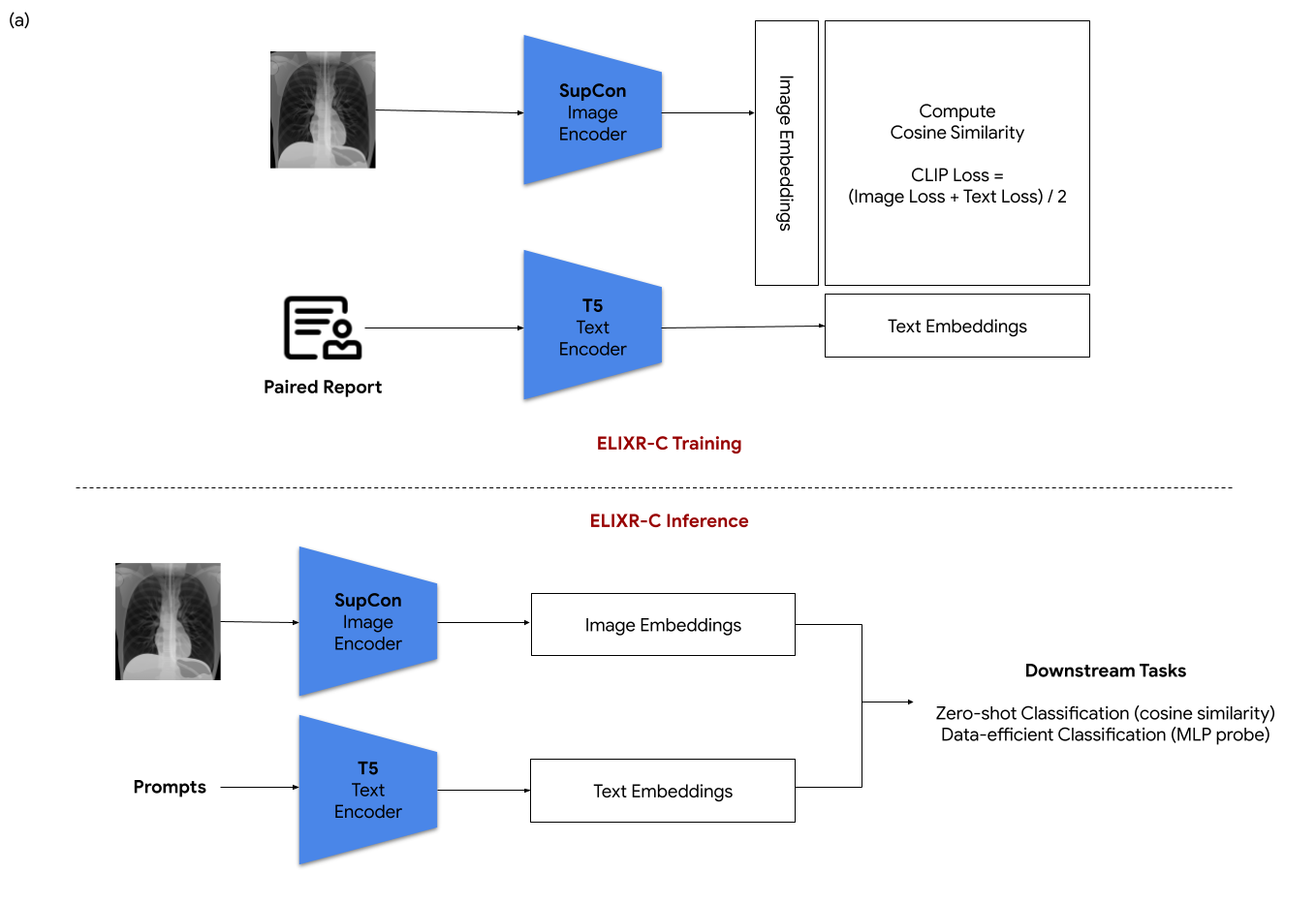
Our approach, which we call Embeddings for Language/Image-aligned X-Rays, or ELIXR, leverages a language-aligned image encoder combined or grafted onto a fixed LLM, PaLM 2, to perform a broad range of tasks. We train this lightweight adapter architecture using images paired with corresponding free-text radiology reports from the MIMIC-CXR dataset. ELIXR achieved state-of-the-art performance on zero-shot chest X-ray (CXR) classification (mean AUC of 0.850 across 13 findings), data-efficient CXR classification (mean AUCs of 0.893 and 0.898 across five findings (atelectasis, cardiomegaly, consolidation, pleural effusion, and pulmonary edema) for 1% (~2,200 images) and 10% (~22,000 images) training data), and semantic search (0.76 normalized discounted cumulative gain (NDCG) across nineteen queries, including perfect retrieval on twelve of them). Compared to existing data-efficient methods including supervised contrastive learning (SupCon), ELIXR required two orders of magnitude less data to reach similar performance. ELIXR also showed promise on CXR vision-language tasks, demonstrating overall accuracies of 58.7% and 62.5% on visual question answering and report quality assurance tasks, respectively. These results suggest that ELIXR is a robust and versatile approach to CXR AI.
翻译:暂无翻译