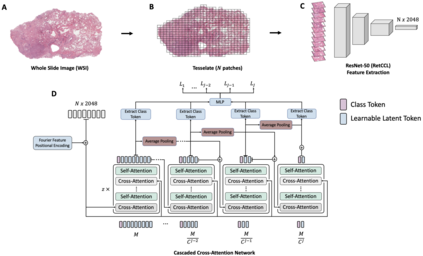
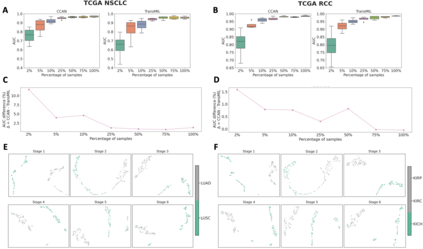
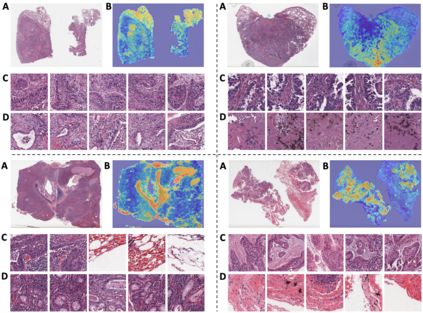
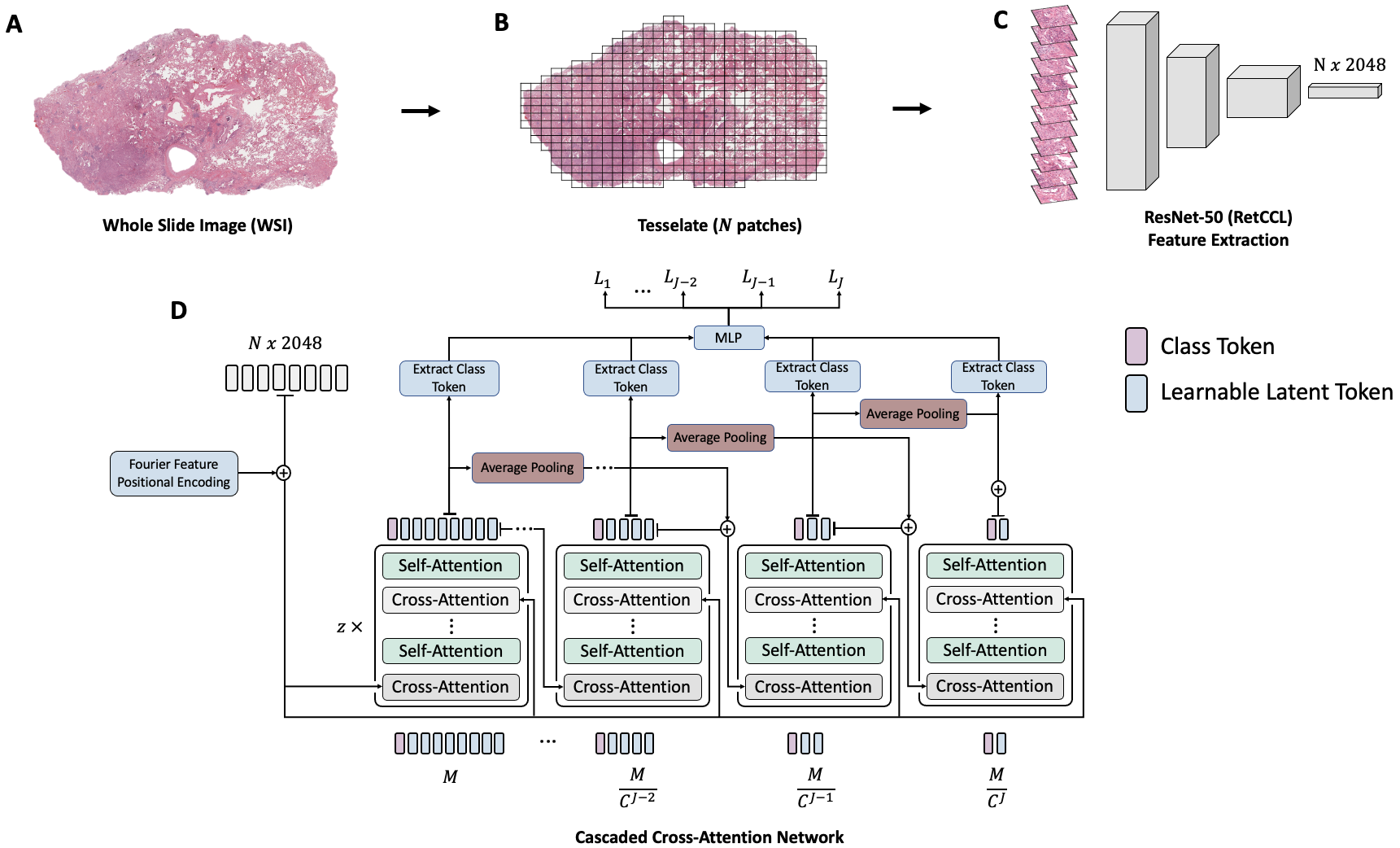
Whole-Slide Imaging allows for the capturing and digitization of high-resolution images of histological specimen. An automated analysis of such images using deep learning models is therefore of high demand. The transformer architecture has been proposed as a possible candidate for effectively leveraging the high-resolution information. Here, the whole-slide image is partitioned into smaller image patches and feature tokens are extracted from these image patches. However, while the conventional transformer allows for a simultaneous processing of a large set of input tokens, the computational demand scales quadratically with the number of input tokens and thus quadratically with the number of image patches. To address this problem we propose a novel cascaded cross-attention network (CCAN) based on the cross-attention mechanism that scales linearly with the number of extracted patches. Our experiments demonstrate that this architecture is at least on-par with and even outperforms other attention-based state-of-the-art methods on two public datasets: On the use-case of lung cancer (TCGA NSCLC) our model reaches a mean area under the receiver operating characteristic (AUC) of 0.970 $\pm$ 0.008 and on renal cancer (TCGA RCC) reaches a mean AUC of 0.985 $\pm$ 0.004. Furthermore, we show that our proposed model is efficient in low-data regimes, making it a promising approach for analyzing whole-slide images in resource-limited settings. To foster research in this direction, we make our code publicly available on GitHub: XXX.
翻译:暂无翻译