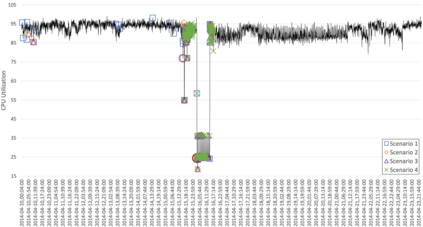
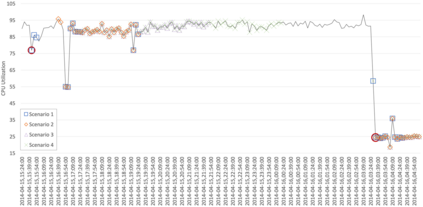
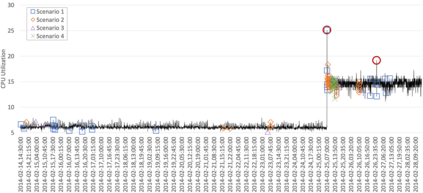
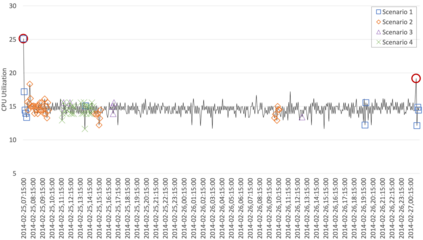
Anomaly detection is the process of identifying unexpected events or ab-normalities in data, and it has been applied in many different areas such as system monitoring, fraud detection, healthcare, intrusion detection, etc. Providing real-time, lightweight, and proactive anomaly detection for time series with neither human intervention nor domain knowledge could be highly valuable since it reduces human effort and enables appropriate countermeasures to be undertaken before a disastrous event occurs. To our knowledge, RePAD (Real-time Proactive Anomaly Detection algorithm) is a generic approach with all above-mentioned features. To achieve real-time and lightweight detection, RePAD utilizes Long Short-Term Memory (LSTM) to detect whether or not each upcoming data point is anomalous based on short-term historical data points. However, it is unclear that how different amounts of historical data points affect the performance of RePAD. Therefore, in this paper, we investigate the impact of different amounts of historical data on RePAD by introducing a set of performance metrics that cover novel detection accuracy measures, time efficiency, readiness, and resource consumption, etc. Empirical experiments based on real-world time series datasets are conducted to evaluate RePAD in different scenarios, and the experimental results are presented and discussed.
翻译:异常探测是查明数据中意外事件或异常现象的过程,已经应用于许多不同领域,如系统监测、欺诈检测、医疗、入侵探测等,例如系统监测、欺诈检测、保健、入侵探测等。 提供实时、轻量和主动异常探测时间序列,而人类干预和领域知识都没有,因此可能非常宝贵,因为它会减少人类的努力,并能够在灾难性事件发生之前采取适当的对策。据我们所知,RePAD(实时主动异常探测算法)是具有上述所有特征的通用方法。为了实现实时和轻度检测,REPAD利用长期短期内存(LSTM)来检测每个即将到来的数据点是否基于短期历史数据点的异常。然而,尚不清楚的是,不同数量的历史数据点如何影响ResPAD的运行。因此,在本文件中,我们调查不同数量的历史数据对REPAD的影响,方法是采用一套包括新发现的准确度度、时间效率、准备和资源消耗等的性能指标。根据真实和已讨论过的实验时间序列中的不同情况,对现实和实验结果进行评估。