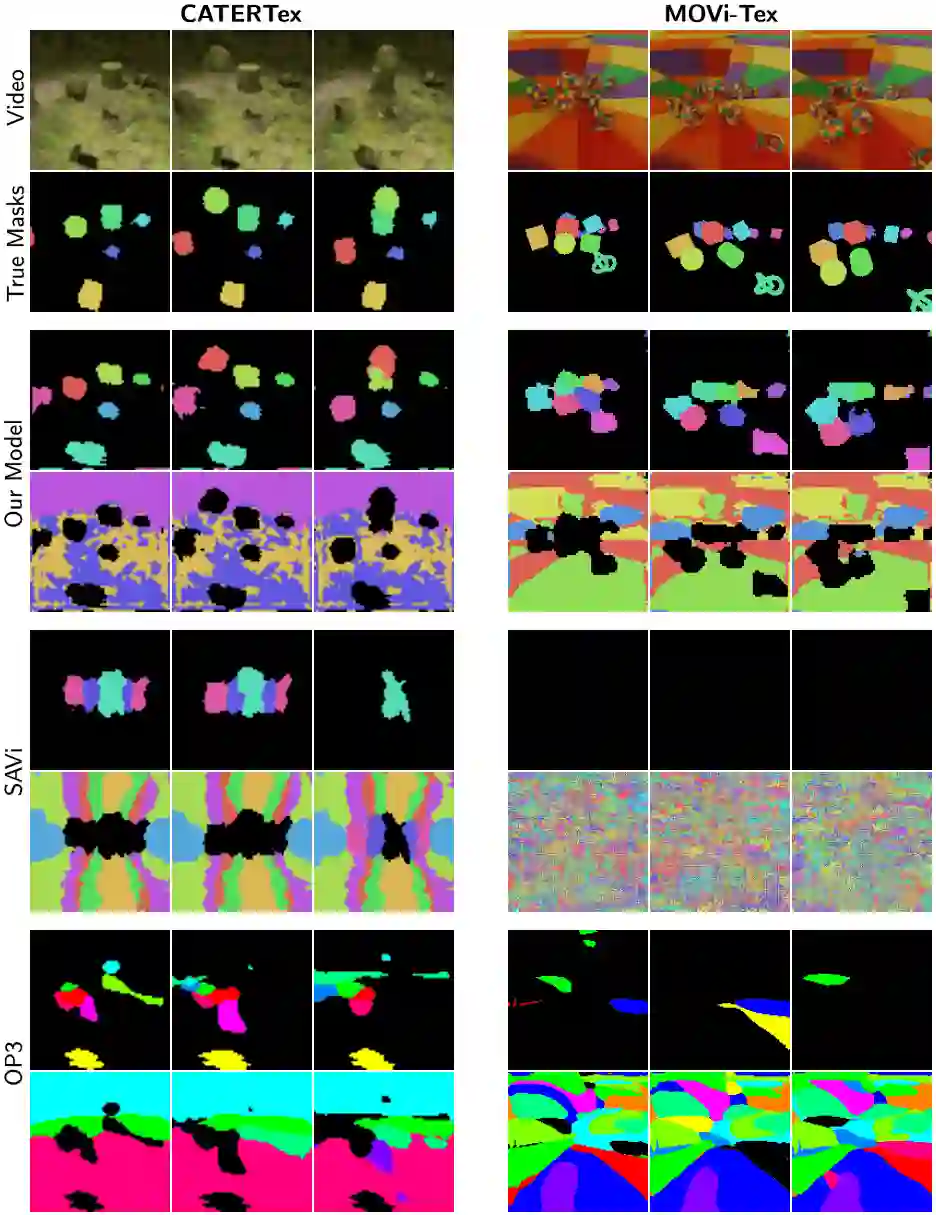
Unsupervised object-centric learning aims to represent the modular, compositional, and causal structure of a scene as a set of object representations and thereby promises to resolve many critical limitations of traditional single-vector representations such as poor systematic generalization. Although there have been many remarkable advances in recent years, one of the most critical problems in this direction has been that previous methods work only with simple and synthetic scenes but not with complex and naturalistic images or videos. In this paper, we propose STEVE, an unsupervised model for object-centric learning in videos. Our proposed model makes a significant advancement by demonstrating its effectiveness on various complex and naturalistic videos unprecedented in this line of research. Interestingly, this is achieved by neither adding complexity to the model architecture nor introducing a new objective or weak supervision. Rather, it is achieved by a surprisingly simple architecture that uses a transformer-based image decoder conditioned on slots and the learning objective is simply to reconstruct the observation. Our experiment results on various complex and naturalistic videos show significant improvements compared to the previous state-of-the-art.
翻译:无人监督的以物体为中心的学习旨在代表一组物体展示的场景的模块、构成和因果结构,从而有望解决传统单一矢量表达方式的许多关键局限性,例如系统化化不良等。虽然近年来取得了许多显著进展,但这一方向上的一个最关键问题是,以往的方法仅涉及简单和合成的场景,而不涉及复杂和自然的图像或视频。在本文中,我们建议采用一个不受监督的视频中以物体为中心的学习模式STEVE。我们提议的模型通过展示其在这一研究领域前所未有的各种复杂和自然的视频的有效性,取得了显著的进步。有趣的是,既未增加模型结构的复杂性,也未引入新的目标或薄弱的监督力,而是通过使用基于变压器的图像解析器在插槽上实现的惊人简单结构,而学习目标只是重建观察。我们关于各种复杂和自然的视频的实验结果与先前的艺术相比,显示了显著的改进。