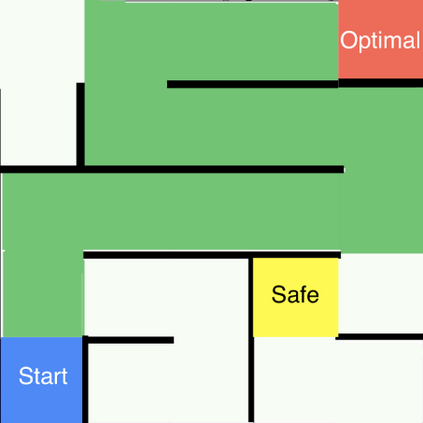
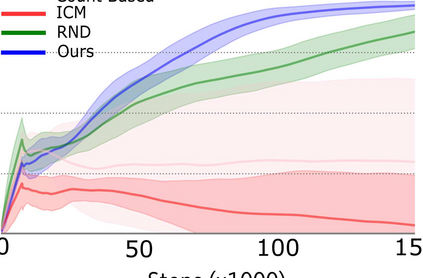
Reward shaping (RS) is a powerful method in reinforcement learning (RL) for overcoming the problem of sparse and uninformative rewards. However, RS relies on manually engineered shaping-reward functions whose construction is typically time-consuming and error-prone. It also requires domain knowledge which runs contrary to the goal of autonomous learning. In this paper, we introduce an automated RS framework in which the shaping-reward function is constructed in a novel stochastic game between two agents. One agent learns both which states to add shaping rewards and their optimal magnitudes and the other agent learns the optimal policy for the task using the shaped rewards. We prove theoretically that our framework, which easily adopts existing RL algorithms, learns to construct a shaping-reward function that is tailored to the task and ensures convergence to higher performing policies for the given task. We demonstrate the superior performance of our method against state-of-the-art RS algorithms in Cartpole and the challenging console games Gravitar, Solaris and Super Mario.
翻译:奖励制(RS)是克服微弱和不信息化奖励问题的强化学习(RL)的有力方法。然而,RS依靠人工设计的塑造奖励功能,而这种功能的构建通常耗时且容易出错。这也需要与自主学习目标相违背的域知识。在本文中,我们引入了一个自动的RS框架,在这个框架中,成型奖励功能在两个代理商之间的新颖的随机游戏中构建。一个代理商学会了两种方法,即国家增加塑造奖励及其最佳幅度,而另一个代理商则学习了使用形状化奖赏完成这项任务的最佳政策。我们从理论上证明,我们的框架很容易采用现有的RL算法,学会构建一个与任务相适应的成型调整功能,并确保与更高执行特定任务的政策相一致。我们展示了我们的方法优于Cartpole中最先进的RS算法以及具有挑战性的拉威塔、索拉里斯和超级马里奥游戏。