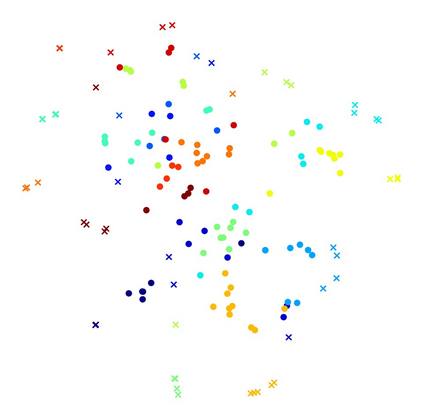
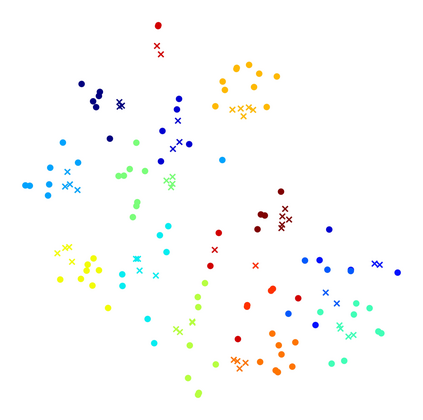
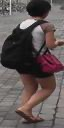Text-based Person Search (TBPS) aims to retrieve images of target pedestrian indicated by textual descriptions. It is essential for TBPS to extract fine-grained local features and align them crossing modality. Existing methods utilize external tools or heavy cross-modal interaction to achieve explicit alignment of cross-modal fine-grained features, which is inefficient and time-consuming. In this work, we propose a Vision-Guided Semantic-Group Network (VGSG) for text-based person search to extract well-aligned fine-grained visual and textual features. In the proposed VGSG, we develop a Semantic-Group Textual Learning (SGTL) module and a Vision-guided Knowledge Transfer (VGKT) module to extract textual local features under the guidance of visual local clues. In SGTL, in order to obtain the local textual representation, we group textual features from the channel dimension based on the semantic cues of language expression, which encourages similar semantic patterns to be grouped implicitly without external tools. In VGKT, a vision-guided attention is employed to extract visual-related textual features, which are inherently aligned with visual cues and termed vision-guided textual features. Furthermore, we design a relational knowledge transfer, including a vision-language similarity transfer and a class probability transfer, to adaptively propagate information of the vision-guided textual features to semantic-group textual features. With the help of relational knowledge transfer, VGKT is capable of aligning semantic-group textual features with corresponding visual features without external tools and complex pairwise interaction. Experimental results on two challenging benchmarks demonstrate its superiority over state-of-the-art methods.
翻译:暂无翻译