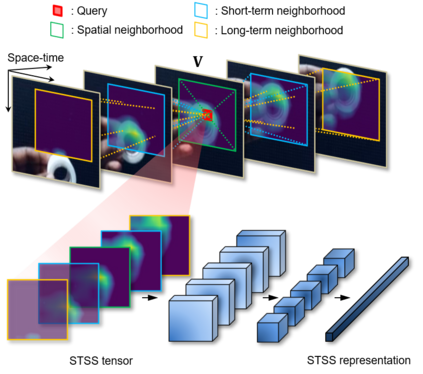
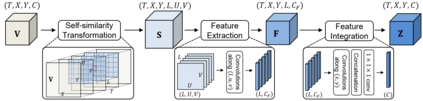
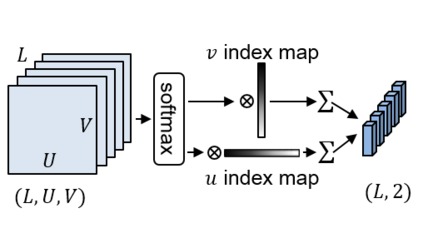
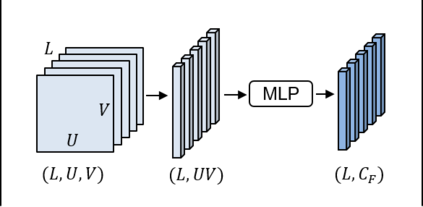
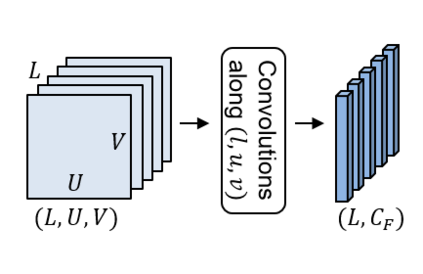
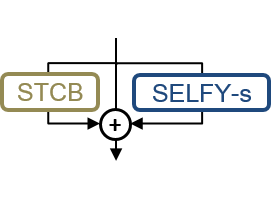
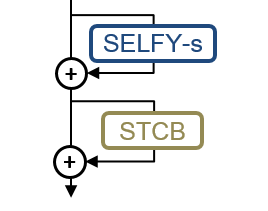
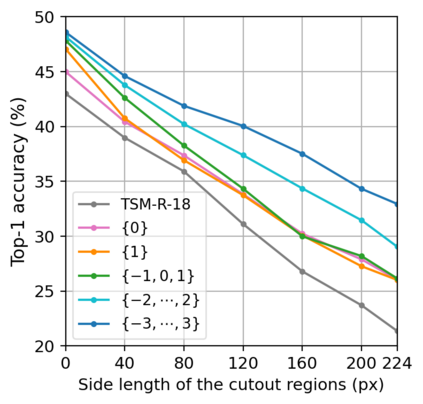
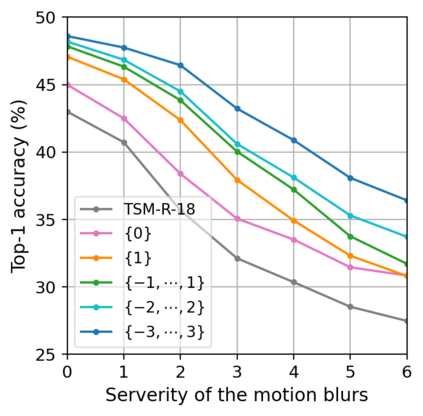
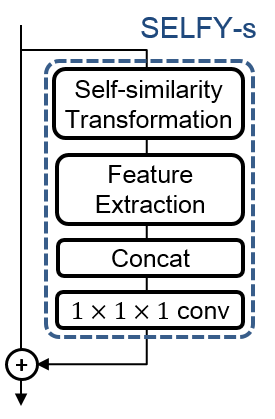
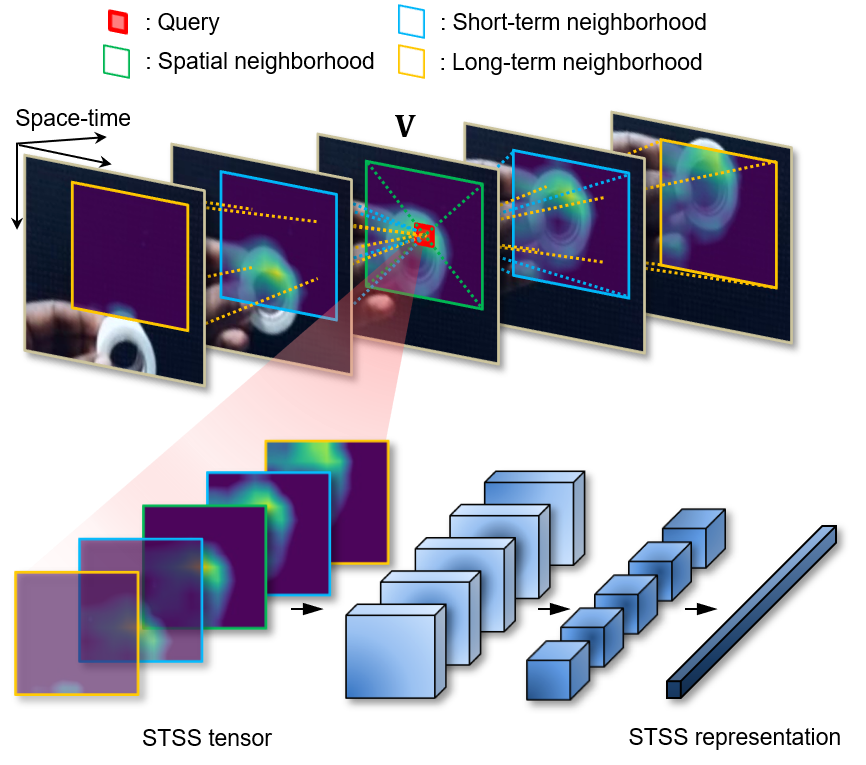
Spatio-temporal convolution often fails to learn motion dynamics in videos and thus an effective motion representation is required for video understanding in the wild. In this paper, we propose a rich and robust motion representation based on spatio-temporal self-similarity (STSS). Given a sequence of frames, STSS represents each local region as similarities to its neighbors in space and time. By converting appearance features into relational values, it enables the learner to better recognize structural patterns in space and time. We leverage the whole volume of STSS and let our model learn to extract an effective motion representation from it. The proposed neural block, dubbed SELFY, can be easily inserted into neural architectures and trained end-to-end without additional supervision. With a sufficient volume of the neighborhood in space and time, it effectively captures long-term interaction and fast motion in the video, leading to robust action recognition. Our experimental analysis demonstrates its superiority over previous methods for motion modeling as well as its complementarity to spatio-temporal features from direct convolution. On the standard action recognition benchmarks, Something-Something-V1 & V2, Diving-48, and FineGym, the proposed method achieves the state-of-the-art results.
翻译:Spatio-时空变迁往往无法在视频中学习运动动态,因此需要有效的运动代表才能在野生视频理解。在本文中,我们提议基于时空自我相似性(STSS)的丰富而有力的运动代表。根据一系列框架,STSS代表每个当地区域与其在空间和时间上的邻居相似。通过将外观特征转换成关联值,使学习者能够更好地了解空间和时间的结构性模式。我们利用STSS的整个数量,让我们的模型学习从中提取有效的运动代表。拟议的神经块(称为SELFY)可以很容易地插入神经结构并培训端对端,而无需额外的监督。如果空间和时间的周围有足够的空间和时间,STSS能够有效地捕捉到长期互动和视频中的快速运动,从而导致强力的行动识别。我们的实验分析表明它优于先前的模拟模式方法,以及它与直接演动中的音波-时空特征的互补性。在标准行动识别基准上,Somes-maphine-V1和Diring方法中,Sim-G2,拟议的Sy-G-py-py-pal-pal-pal-pal-pal-pal-pal-pal-pal-pat-pal-pal-pat-pal-pres-pres-pat-pat-pal-pres-pal-pres-pres-pres-pat-pat-pat-pat-pres-pal-pres-pres-pres-pres-pres-pres-pres-pres-pres-pal-pres-pres-pal-pal-pat-pat-pres-pres-pres-s-pres-pres-pres-pal-pal-pal-s-pal-pres-p-p-p-p-s-pal-pal-pat-pat-s-pal-pal-pal-pal-pal-pal-pal-pal-pal-pal-pal-pal-pal-pal-pal-pat-pat-pat-pres-pres-pres-pal-pres