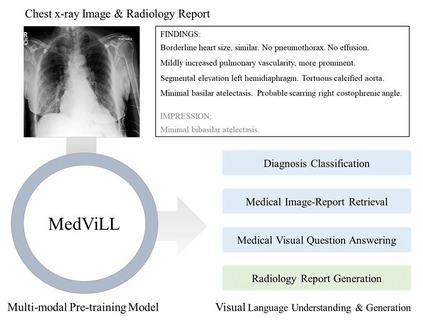
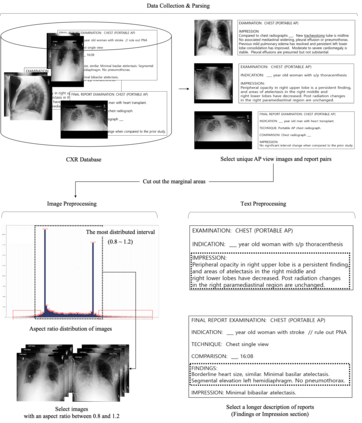
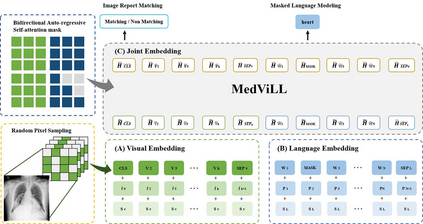
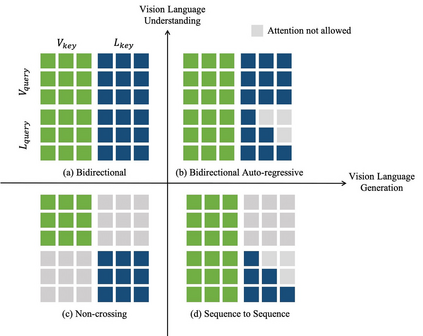
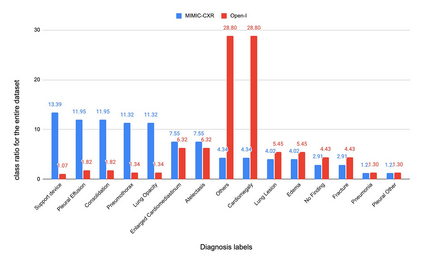
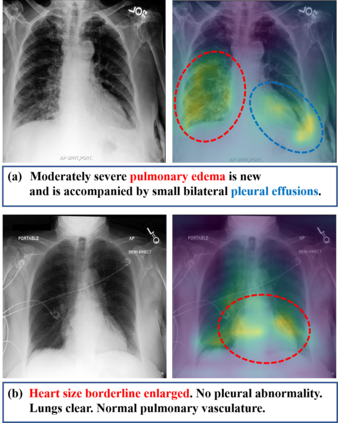
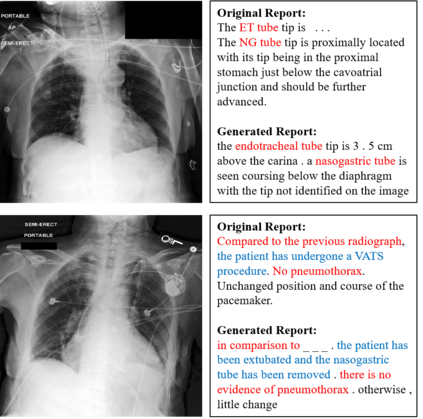
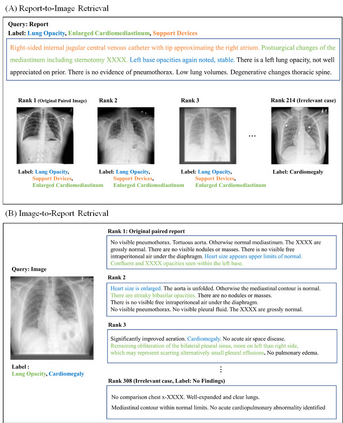
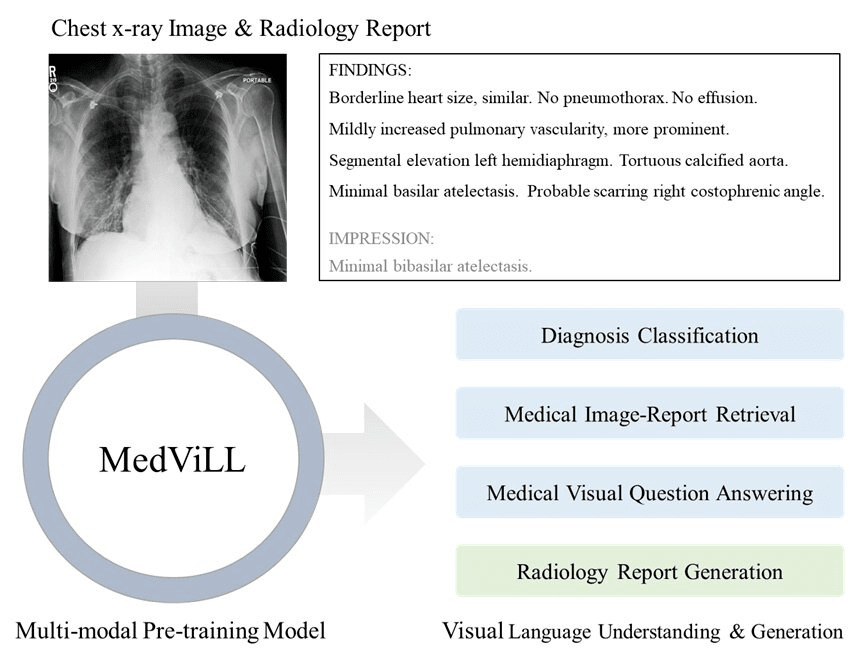
Recently a number of studies demonstrated impressive performance on diverse vision-language multimodal tasks such as image captioning and visual question answering by extending the self-attention based Transformer architecture with multimodal pre-training objectives. Despite its huge potential, vision-language multimodal pre-training in the medical domain has only recently received attention, and only demonstrated improved diagnosis accuracy of vision-language pre-trained models. In this work we explore a broad set of multimodal representation learning tasks in the medical domain, specifically using radiology images and the unstructured report. We propose a new model which adopts a Transformer based architecture combined with a novel multimodal attention masking scheme to maximize generalization performance for both vision-language understanding task (e.g., diagnosis classification) and vision-language generation task (e.g., radiology report generation). By rigorously evaluating the proposed model on four downstream tasks with three radiographic image-text datasets (MIMIC-CXR, Open-I, and VQA-RAD), we empirically demonstrate the superior downstream task performance and generality of our model against various baselines including task specific architectures. In addition, we qualitatively analyze our model by showing the results of retrieved image-report pairs, the attention map visualization, and generated reports. Our proposed multimodal pre-training model could flexibly adapt to multiple downstream tasks of vision-language understanding and generation with a novel self-attention scheme. We believe that our approach can provide the basis for a wide range of interpretations of vision-language multimodal in the medical domain.
翻译:最近,一些研究显示,在多种视觉语言多式联运任务(如图像说明和直观回答)上,通过扩大基于自我注意的变异器结构,扩大具有多式培训前目标的多式联运结构,取得了令人印象深刻的成绩。尽管具有巨大的潜力,医疗领域的视觉语言多式联运预培训直到最近才得到关注,而且只是展示了视觉语言先行模式的诊断准确性有所提高。在这项工作中,我们探索了医疗领域的一套广泛的多式代表学习任务,特别是使用放射图像和无结构报告。我们提出了一个新模式,采用基于变异器的架构,加上新的多式联运遮掩关注计划,以最大限度地提高视野语言理解任务(如诊断分类)和视觉语言生成任务(如放射学报告的生成)的普及性业绩。我们严格评估了四种下游任务的拟议模式,并用三种幅幅幅幅图像文本数据集(MIMIC-CXR、Open-I和VQA-RA-RA-RAD),我们从经验上展示了我们模型的高级下游任务业绩和概括性任务,包括任务特定结构。此外,我们从质量上分析我们的模型,通过展示了我们所拟的多式报告生成的图式理解基础,可以提供我们提出的图式版本版本版本版本版本报告。