
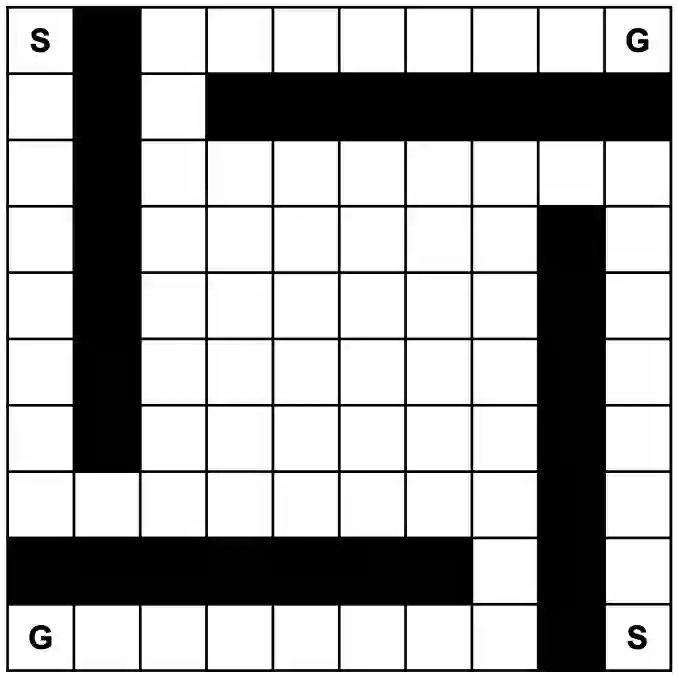
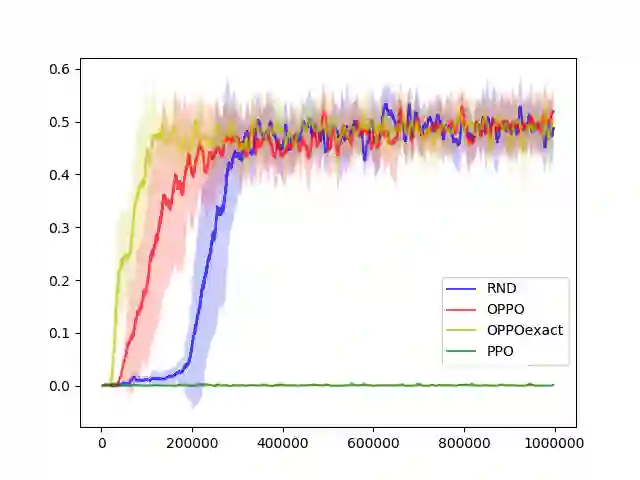
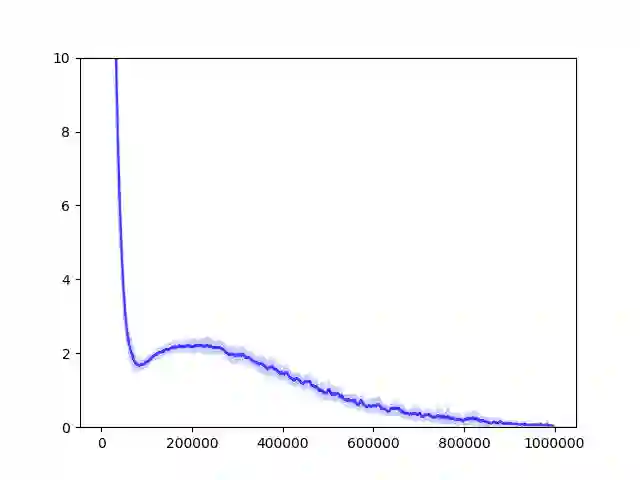
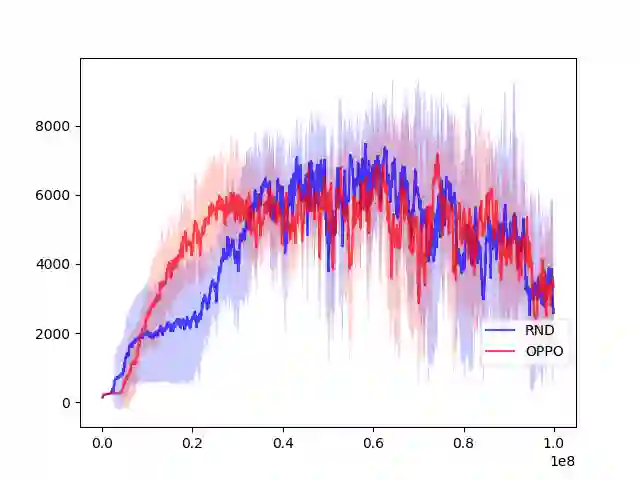
Reinforcement Learning, a machine learning framework for training an autonomous agent based on rewards, has shown outstanding results in various domains. However, it is known that learning a good policy is difficult in a domain where rewards are rare. We propose a method, optimistic proximal policy optimization (OPPO) to alleviate this difficulty. OPPO considers the uncertainty of the estimated total return and optimistically evaluates the policy based on that amount. We show that OPPO outperforms the existing methods in a tabular task.
翻译:强化学习是培训基于奖励的自主机构的一个机械学习框架,在各个领域都取得了突出的成果,然而,众所周知,在一个少有奖励的领域,很难学习好的政策,我们提出一种方法,即乐观的准政策优化(OPPO)来缓解这一困难。OPPO考虑估计总回报率的不确定性,乐观地评价以这一数额为基础的政策。我们显示OPPO在一项列表任务中优于现有方法。

相关内容

Arxiv
6+阅读 · 2018年3月30日
相关主题



相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2018年3月30日