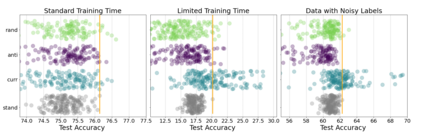
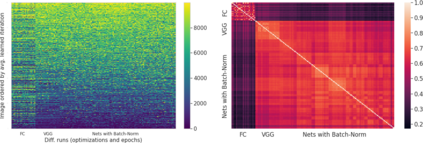
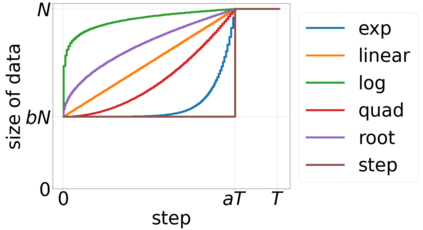
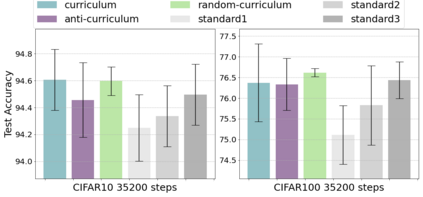
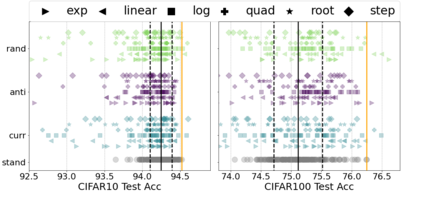
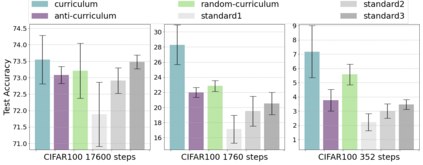
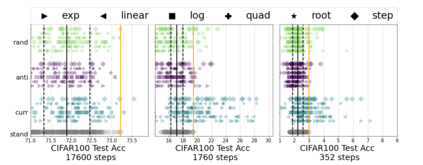
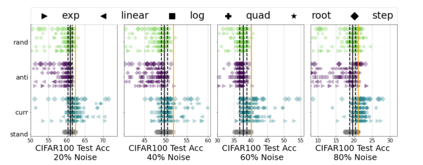
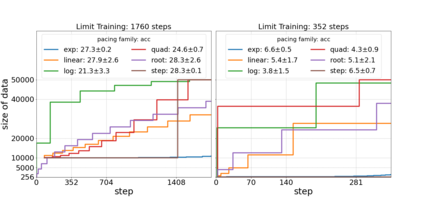
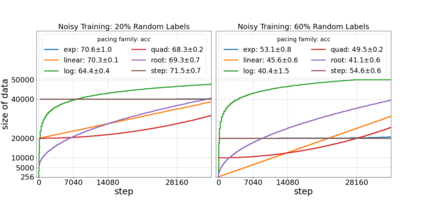
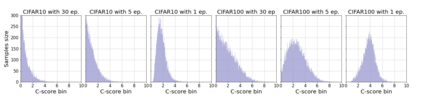
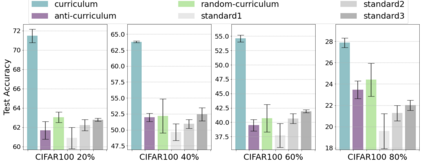
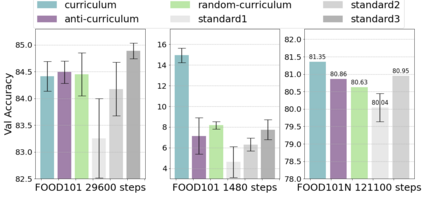
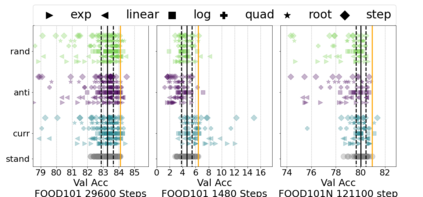
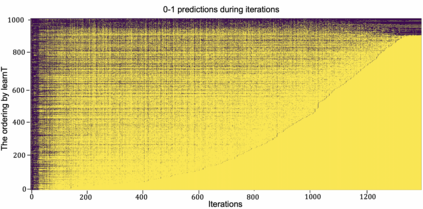
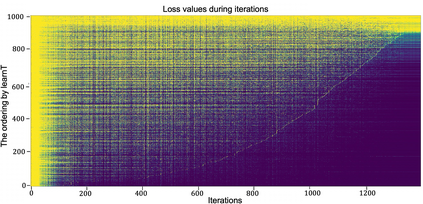
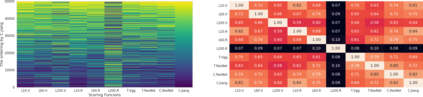
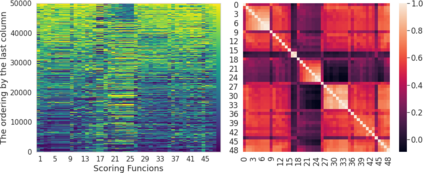
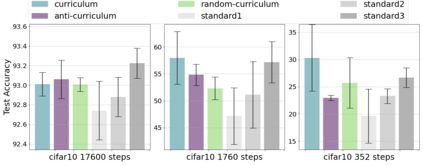
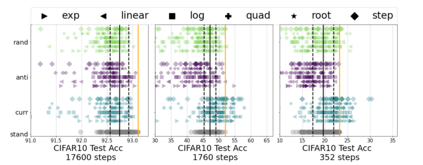
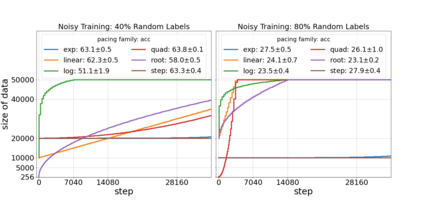
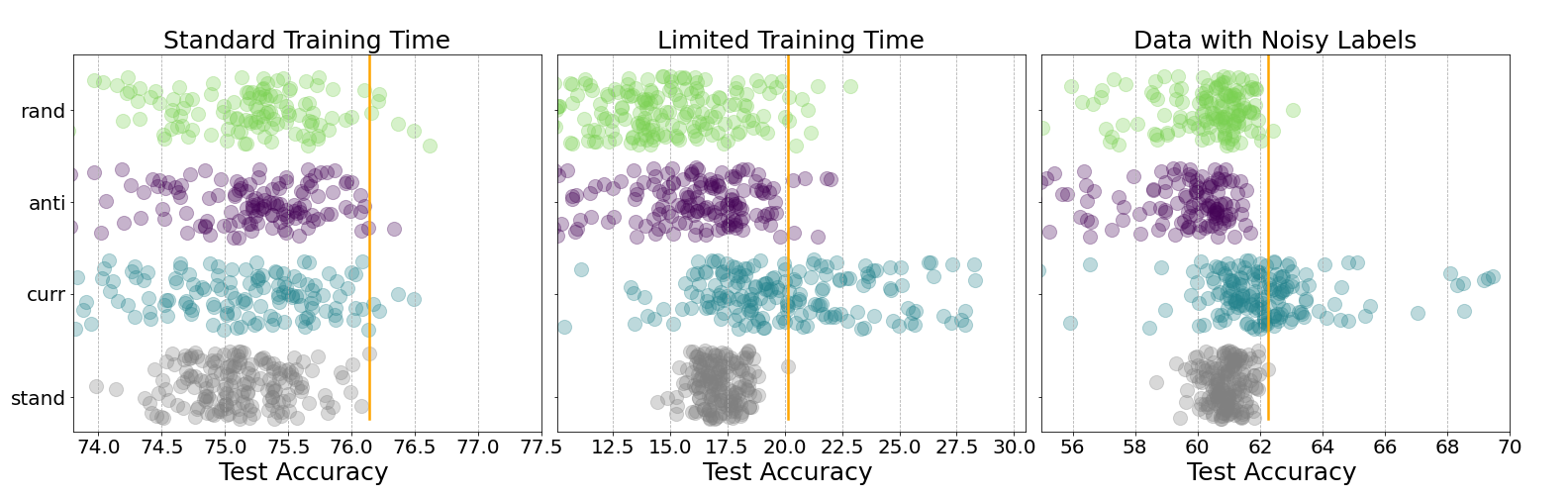
Inspired by human learning, researchers have proposed ordering examples during training based on their difficulty. Both curriculum learning, exposing a network to easier examples early in training, and anti-curriculum learning, showing the most difficult examples first, have been suggested as improvements to the standard i.i.d. training. In this work, we set out to investigate the relative benefits of ordered learning. We first investigate the \emph{implicit curricula} resulting from architectural and optimization bias and find that samples are learned in a highly consistent order. Next, to quantify the benefit of \emph{explicit curricula}, we conduct extensive experiments over thousands of orderings spanning three kinds of learning: curriculum, anti-curriculum, and random-curriculum -- in which the size of the training dataset is dynamically increased over time, but the examples are randomly ordered. We find that for standard benchmark datasets, curricula have only marginal benefits, and that randomly ordered samples perform as well or better than curricula and anti-curricula, suggesting that any benefit is entirely due to the dynamic training set size. Inspired by common use cases of curriculum learning in practice, we investigate the role of limited training time budget and noisy data in the success of curriculum learning. Our experiments demonstrate that curriculum, but not anti-curriculum can indeed improve the performance either with limited training time budget or in existence of noisy data.
翻译:在人类学习的启发下,研究人员在培训过程中根据其困难而提议了按部就班的例子。一方面,课程学习,使网络在培训初期暴露为较容易的例子,另一方面,反课程学习,首先展示最困难的例子,这都是对标准i.d.培训的改进。在这项工作中,我们开始调查按部就班学习的相对好处。我们首先调查建筑和优化偏差所产生的课程,发现抽样的学习顺序非常一致。另一方面,为了量化\emph{Expliculate 课程的好处,我们广泛试验了数千个包括三种学习的订单:课程、反课程和随机课程 -- -- 其中培训数据集的规模随着时间的推移而变化地增加,但实例是随机排列的。我们发现,对于标准基准数据集而言,课程只产生微不足道的好处,随机订购的样本比课程和反课程要好,表明任何好处都完全归因于动态培训所设定的大小。我们通过常规的学习课程,我们通过学习的学习学习学习成绩,可以证明在预算实践中的学习成绩是有限的,我们学习学习成绩,我们学习的成绩是有限的,我们学习成绩的成绩,我们学习课程的成绩是有限的。