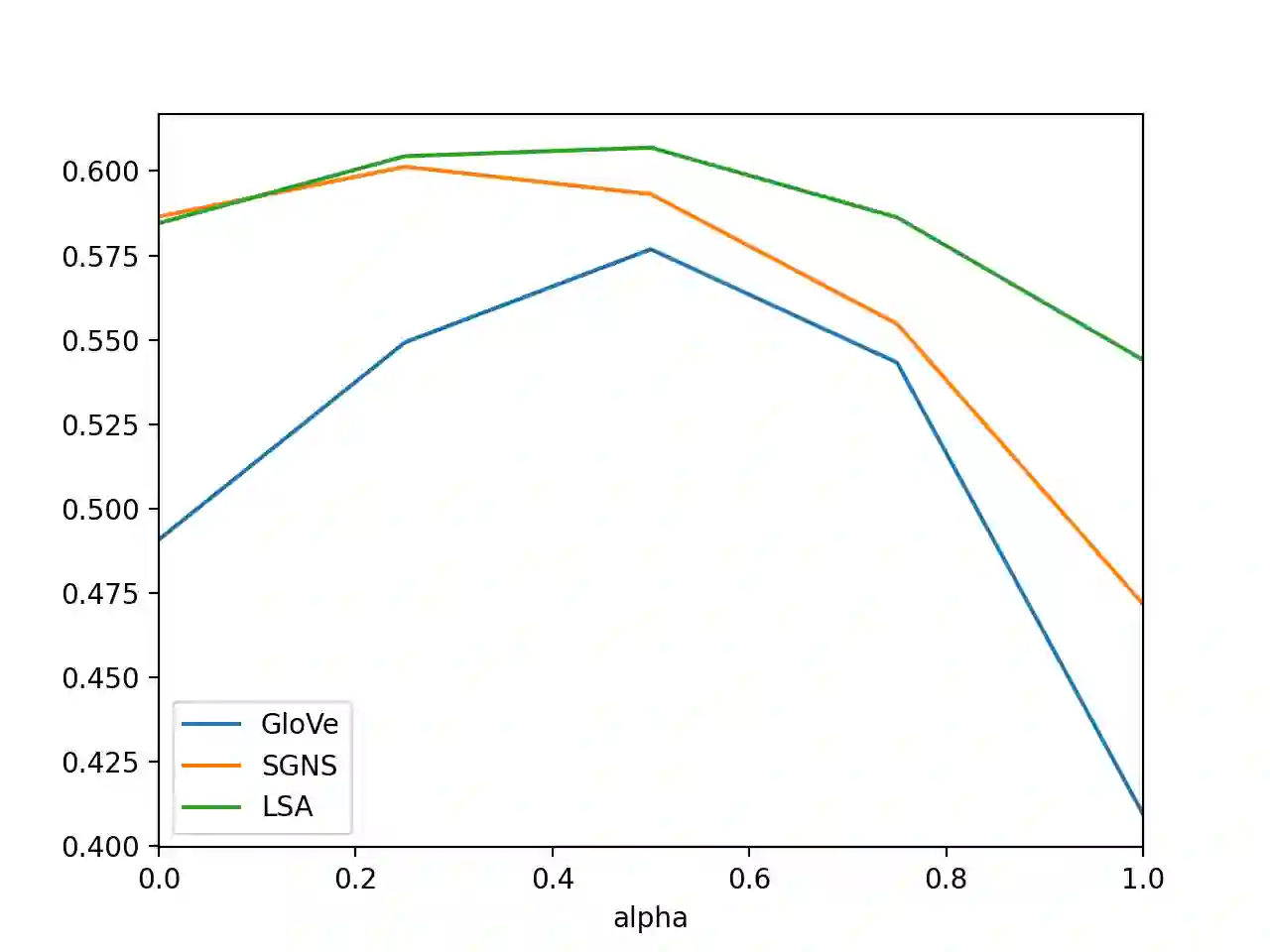
Given multiple source word embeddings learnt using diverse algorithms and lexical resources, meta word embedding learning methods attempt to learn more accurate and wide-coverage word embeddings. Prior work on meta-embedding has repeatedly discovered that simple vector concatenation of the source embeddings to be a competitive baseline. However, it remains unclear as to why and when simple vector concatenation can produce accurate meta-embeddings. We show that weighted concatenation can be seen as a spectrum matching operation between each source embedding and the meta-embedding, minimising the pairwise inner-product loss. Following this theoretical analysis, we propose two \emph{unsupervised} methods to learn the optimal concatenation weights for creating meta-embeddings from a given set of source embeddings. Experimental results on multiple benchmark datasets show that the proposed weighted concatenated meta-embedding methods outperform previously proposed meta-embedding learning methods.
翻译:鉴于使用多种算法和词汇资源学习的多种源词嵌入,元词嵌入学习方法试图学习更准确和广泛覆盖的嵌入词。元件嵌入法先前的工作一再发现,源嵌入的简单矢量融合是一个竞争性基线。然而,对于为什么以及当简单的矢量融合能够产生准确的元集时,仍然不清楚。我们显示,加权融合可以被视为每个源嵌入和元集之间的频谱匹配操作,最小化对称的内产产品损失。根据这一理论分析,我们提出两个\emph{unsupervised}方法,以学习从特定源嵌入中创建元集的最佳配置权重。多个基准数据集的实验结果显示,拟议的加权组合元集方法超越了先前提议的元集式学习方法。