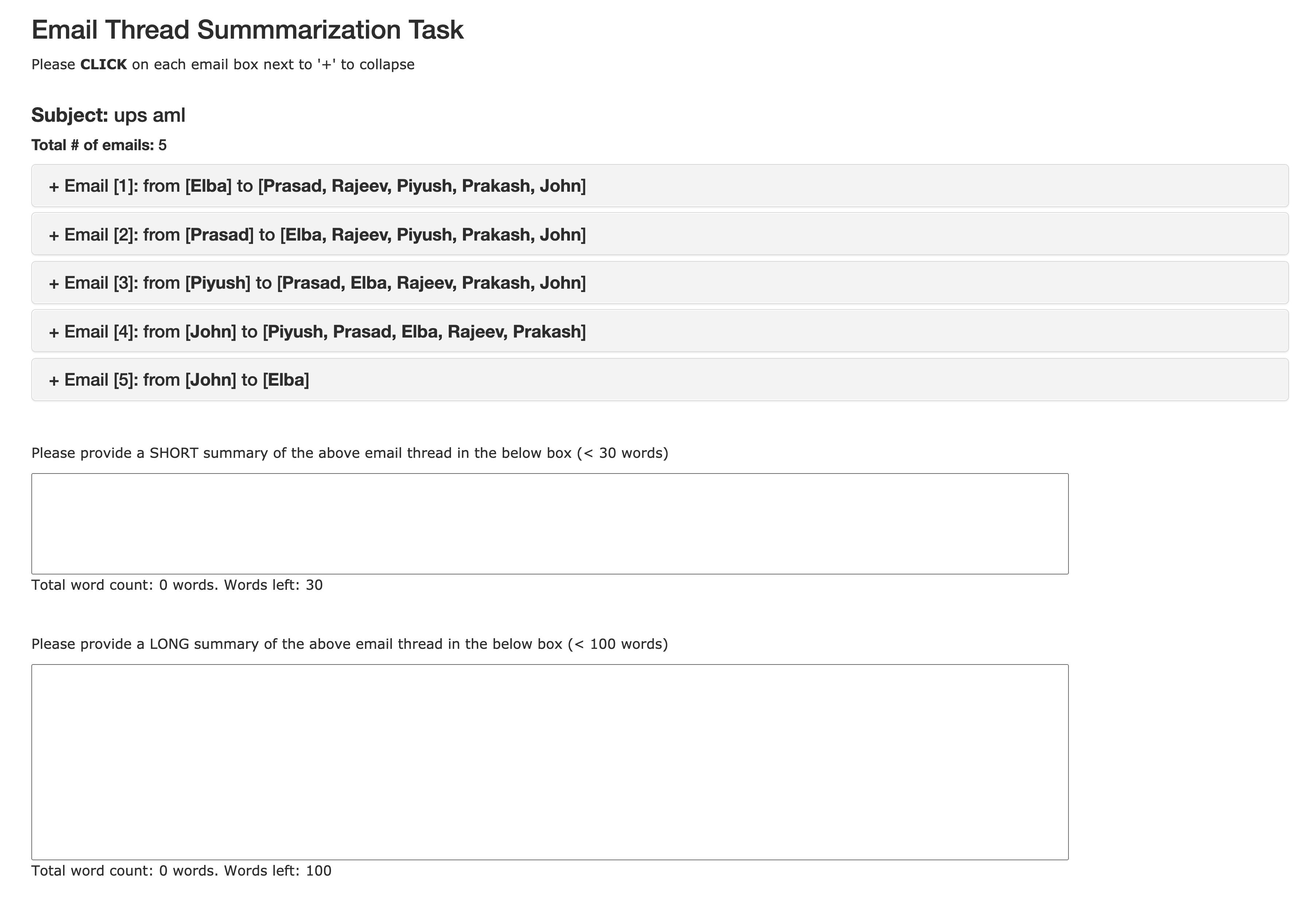
Recent years have brought about an interest in the challenging task of summarizing conversation threads (meetings, online discussions, etc.). Such summaries help analysis of the long text to quickly catch up with the decisions made and thus improve our work or communication efficiency. To spur research in thread summarization, we have developed an abstractive Email Thread Summarization (EmailSum) dataset, which contains human-annotated short (<30 words) and long (<100 words) summaries of 2549 email threads (each containing 3 to 10 emails) over a wide variety of topics. We perform a comprehensive empirical study to explore different summarization techniques (including extractive and abstractive methods, single-document and hierarchical models, as well as transfer and semisupervised learning) and conduct human evaluations on both short and long summary generation tasks. Our results reveal the key challenges of current abstractive summarization models in this task, such as understanding the sender's intent and identifying the roles of sender and receiver. Furthermore, we find that widely used automatic evaluation metrics (ROUGE, BERTScore) are weakly correlated with human judgments on this email thread summarization task. Hence, we emphasize the importance of human evaluation and the development of better metrics by the community. Our code and summary data have been made available at: https://github.com/ZhangShiyue/EmailSum
翻译:近些年来,大家对总结各种议题的对话线索(会议、在线讨论等)这一具有挑战性的任务产生了兴趣。这些摘要有助于分析长篇文章,以便迅速赶上所作决定,从而改进我们的工作或通信效率。为了刺激对线索的总结研究,我们开发了一个抽象的Email Thread Summarization(EmailSummarization)(EmailSummarization)(EmailSum)数据集,其中包含人文注释短片(<30个字)和长篇(<100个字)的2549个电子邮件线索摘要(每个短片包含3至10个电子邮件)。我们进行了一项全面的经验性研究,以探索不同的总结技术(包括采掘和抽象方法、单份文件和等级模型,以及转移和半监督学习),并对短长篇摘要生成任务进行人文评估。我们的结果揭示了当前抽象的总结模型在这项工作中的主要挑战,例如了解发送者的意图和确定发件人和接收人的作用。此外,我们发现广泛使用的自动评价指标(ROUGE、BERSTScore)与人类判断系统对这个电子邮件/Simalimalalimal dalization的进度进行了较重要的评估。我们强调了这个电子邮件/TourSRimalimalimalimdudududududududududududududududududududududududududududustrs。我们的数据。