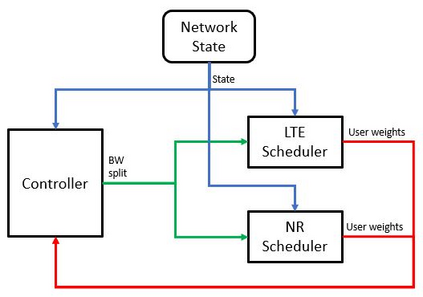
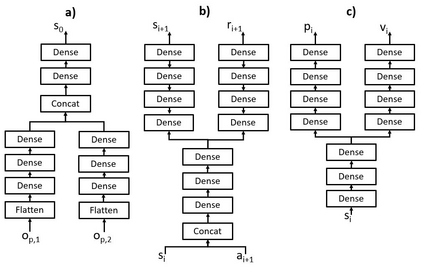
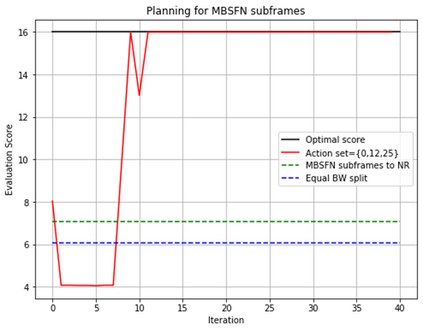
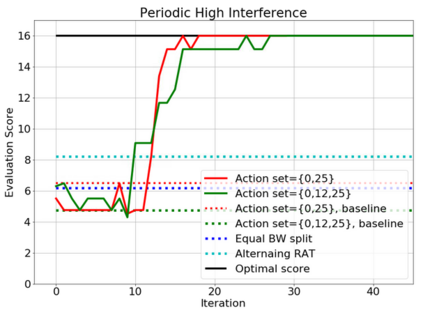
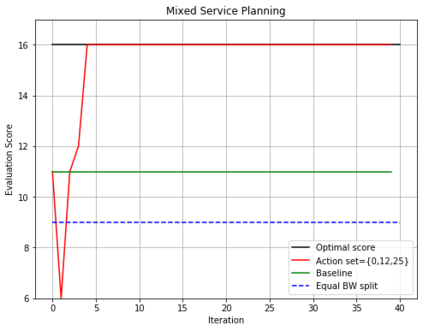
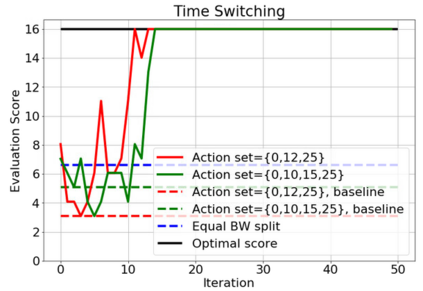
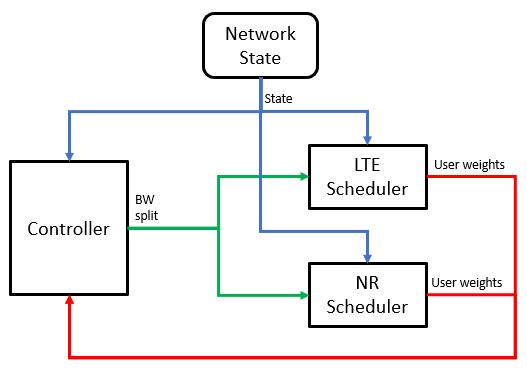
In this paper, a proactive dynamic spectrum sharing scheme between 4G and 5G systems is proposed. In particular, a controller decides on the resource split between NR and LTE every subframe while accounting for future network states such as high interference subframes and multimedia broadcast single frequency network (MBSFN) subframes. To solve this problem, a deep reinforcement learning (RL) algorithm based on Monte Carlo Tree Search (MCTS) is proposed. The introduced deep RL architecture is trained offline whereby the controller predicts a sequence of future states of the wireless access network by simulating hypothetical bandwidth splits over time starting from the current network state. The action sequence resulting in the best reward is then assigned. This is realized by predicting the quantities most directly relevant to planning, i.e., the reward, the action probabilities, and the value for each network state. Simulation results show that the proposed scheme is able to take actions while accounting for future states instead of being greedy in each subframe. The results also show that the proposed framework improves system-level performance.
翻译:本文提出了4G 和 5G 系统之间的主动动态频谱共享计划。 特别是, 控制员决定NR 和 LTE 每个子框架之间的资源分割, 同时考虑到未来的网络状态, 如高干扰子框架和多媒体广播单频网络( MBSFN) 子框架。 为了解决这个问题, 提议了一个基于蒙特卡洛树搜索( MCTS) 的深度强化学习算法。 引入的深层 RL 结构经过培训, 由控制员通过模拟从当前网络状态开始的假想带宽分解来预测无线接入网络未来状态的序列。 最终获得最佳奖赏的行动序列随后被指定。 这是通过预测与规划最直接相关的数量来实现的, 即奖赏、 行动概率和每个网络状态的价值。 模拟结果表明, 拟议的计划能够在计算未来国家而不是每个子框架贪婪的情况下采取行动。 其结果还表明, 拟议的框架提高了系统水平的绩效。