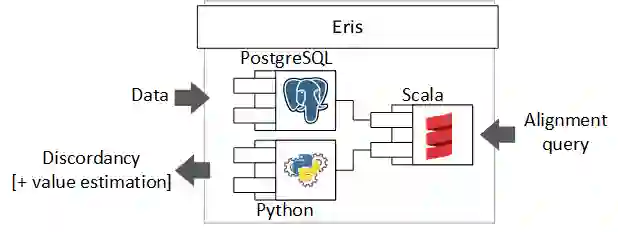
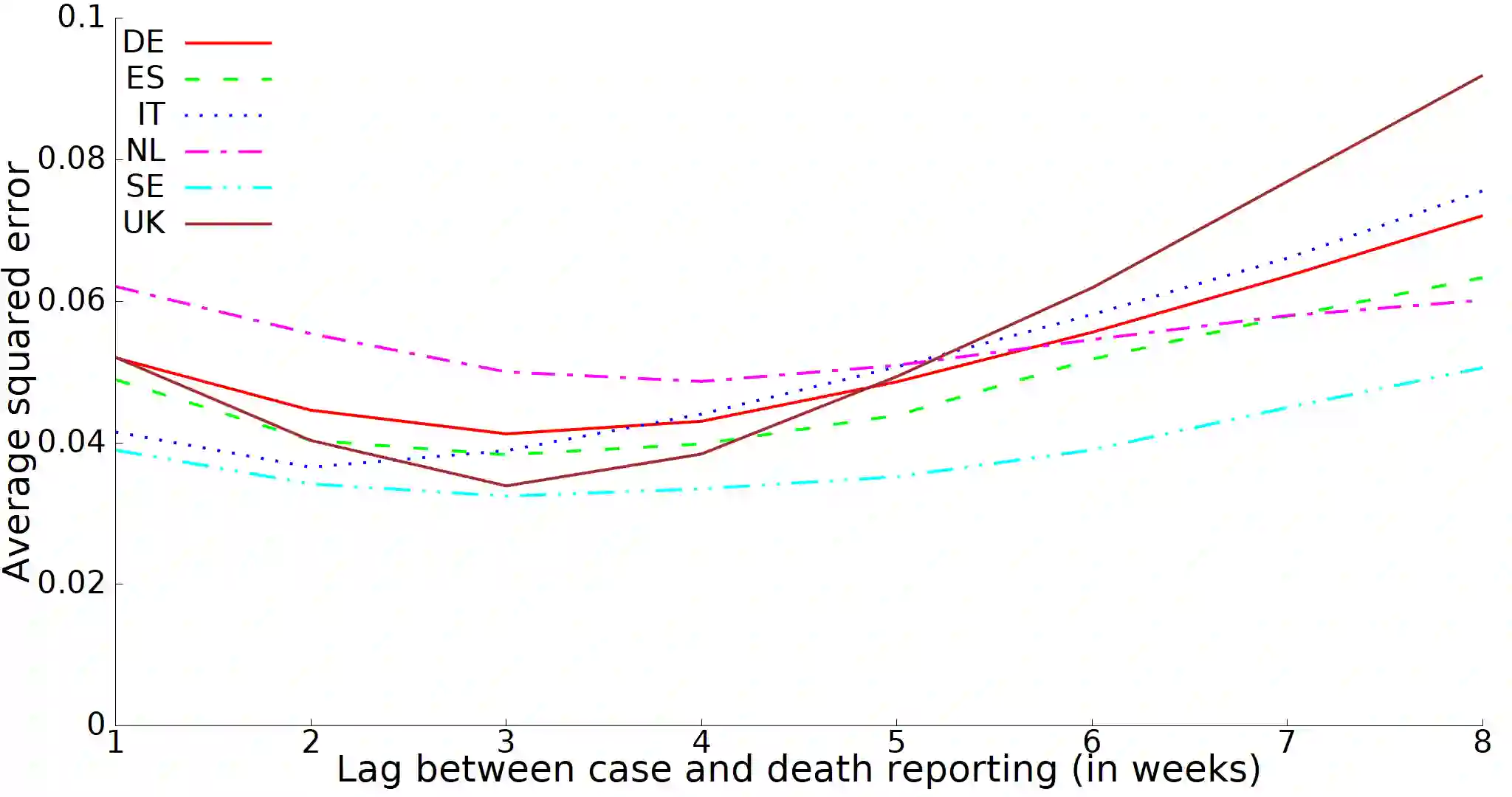
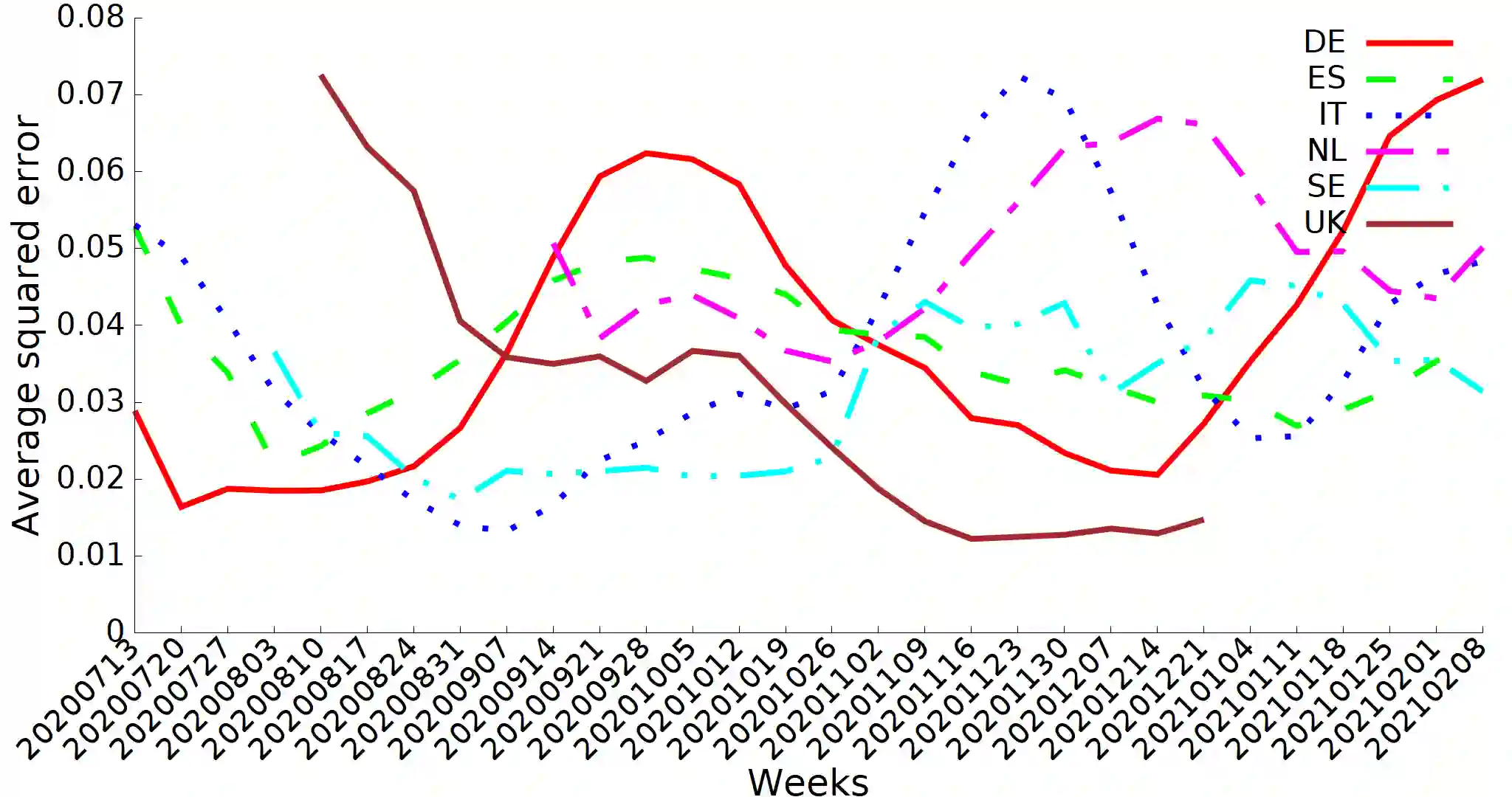
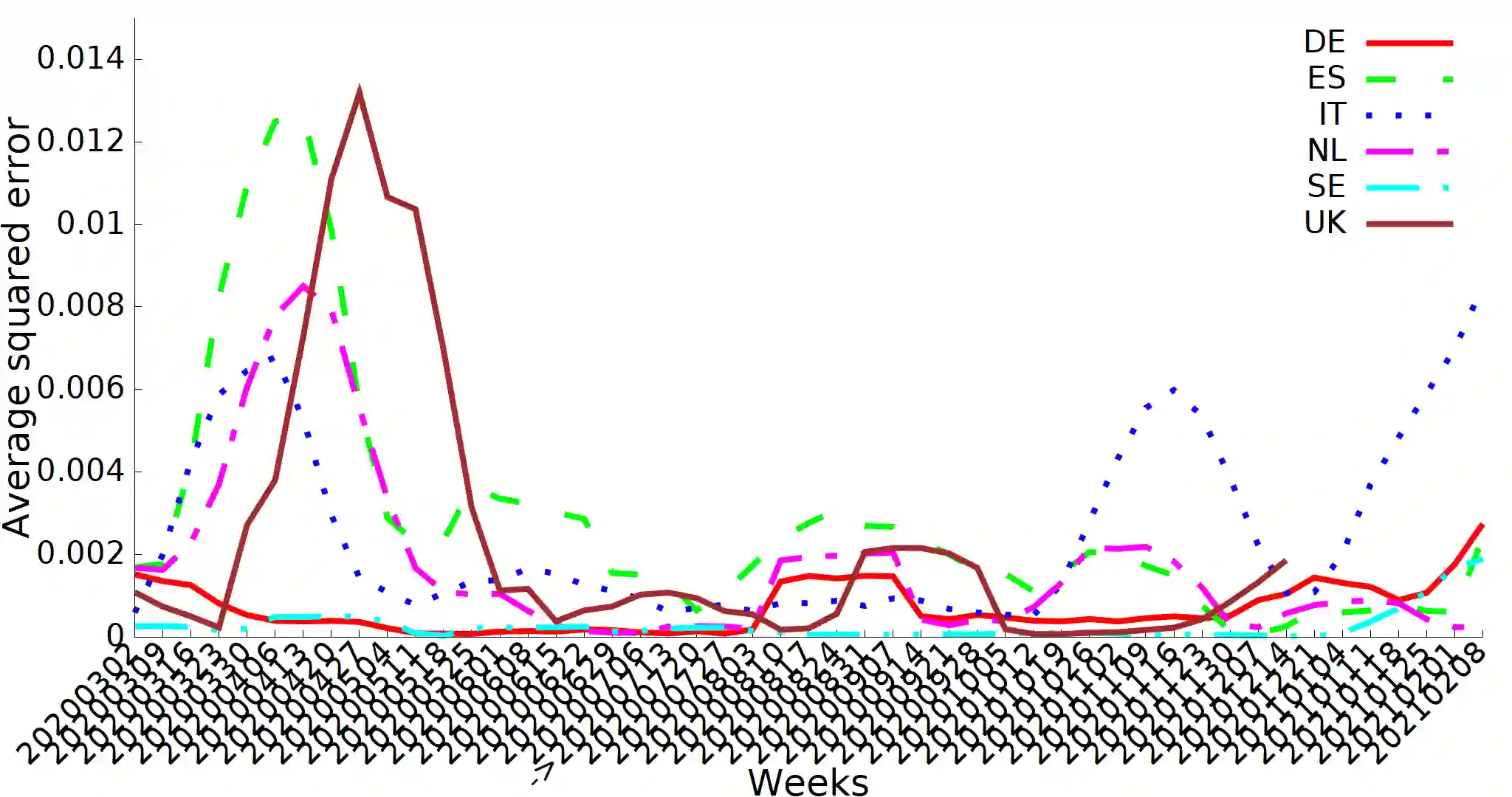
Data integration is a classical problem in databases, typically decomposed into schema matching, entity matching and record merging. To solve the latter, it is mostly assumed that ground truth can be determined, either as master data or from user feedback. However, in many cases, this is not the case because firstly the merging processes cannot be accurate enough, and also the data gathering processes in the different sources are simply imperfect and cannot provide high quality data. Instead of enforcing consistency, we propose to evaluate how concordant or discordant sources are as a measure of trustworthiness (the more discordant are the sources, the less we can trust their data). Thus, we define the discord measurement problem in which given a set of uncertain raw observations or aggregate results (such as case/hospitalization/death data relevant to COVID-19) and information on the alignment of different data (for example, cases and deaths), we wish to assess whether the different sources are concordant, or if not, measure how discordant they are. We also define a set of algebraic operators to describe the alignments, together with two alternative relational implementations that reduce the problem to linear or quadratic programming. These are evaluated against both COVID-19 and synthetic data, and our experimental results show that discordancy measurement can be performed efficiently in realistic situations.
翻译:在数据库中,数据整合是一个典型的问题,通常被分解成系统匹配、实体匹配和记录合并。为了解决后者,我们主要假设地面真相可以确定,要么是主数据,要么是用户反馈。然而,在许多情况下,情况并非如此,因为首先合并过程不能足够准确,而且不同来源的数据收集过程只是不完善,不能提供高质量的数据。我们建议,非但没有执行一致性,而是评价各种来源的一致或不协调来源如何作为一种可信任性衡量标准(来源越多,我们就越不信任它们的数据)。因此,我们界定了不协调的测量问题,因为存在一系列不确定的原始观察或综合结果(例如与COVID-19相关的案例/热化/死亡数据),以及不同数据(例如,案例和死亡)的协调统一信息,我们希望评估不同来源是否一致,或者如果不一致,衡量它们之间的不协调程度。我们还定义了一组代数操作者来描述这些匹配情况,同时界定了两种可选择的关联性关系,即如何减少与合成-19测量结果之间的问题,从而能够有效地显示我们的实验性-对比性数据。