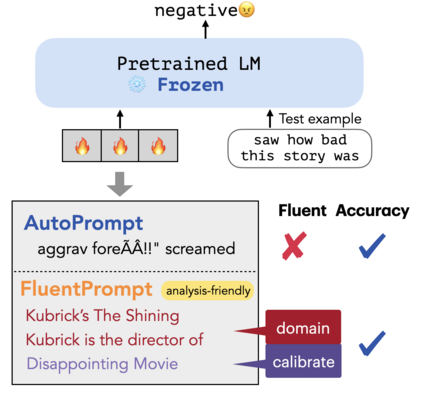
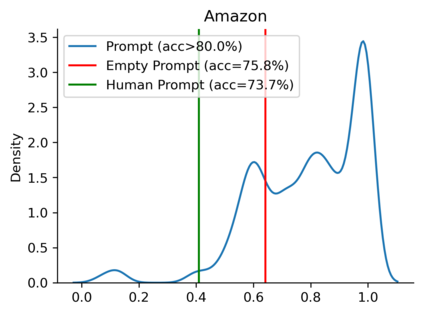
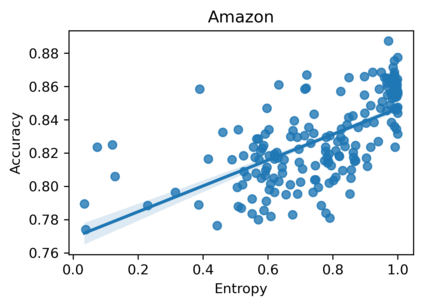
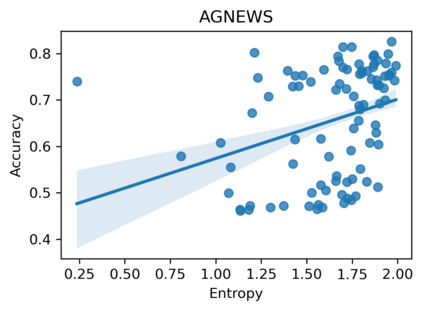
Large language models can perform new tasks in a zero-shot fashion, given natural language prompts that specify the desired behavior. Such prompts are typically hand engineered, but can also be learned with gradient-based methods from labeled data. However, it is underexplored what factors make the prompts effective, especially when the prompts are natural language. In this paper, we investigate common attributes shared by effective prompts. We first propose a human readable prompt tuning method (F LUENT P ROMPT) based on Langevin dynamics that incorporates a fluency constraint to find a diverse distribution of effective and fluent prompts. Our analysis reveals that effective prompts are topically related to the task domain and calibrate the prior probability of label words. Based on these findings, we also propose a method for generating prompts using only unlabeled data, outperforming strong baselines by an average of 7.0% accuracy across three tasks.
翻译:大型语言模型可以以零速方式执行新任务, 以自然语言提示来指定想要的行为。 这种提示通常是手工设计的, 但也可以用基于梯度的方法从标签的数据中学习 。 但是, 它没有被充分探讨哪些因素使提示有效, 特别是当提示是自然语言时。 在本文中, 我们调查有效提示共享的共同属性 。 我们首先根据兰格文动态, 提出了一个人类可读快速调试方法( F F LUENT P ROMPT ), 其中包含一种精密限制, 以找到不同分布的有效和流畅的提示。 我们的分析显示, 有效提示与任务领域主题相关, 并校准先前标签词的概率 。 基于这些发现, 我们还提出一种方法, 仅使用未标的数据生成提示, 以三种任务平均7.0%的精准度超过强的基线 。