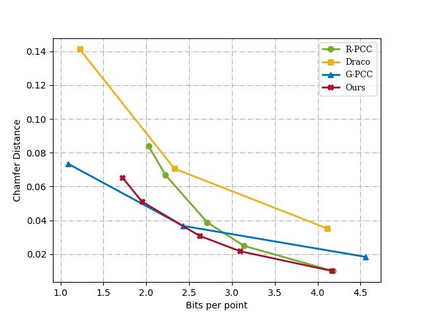
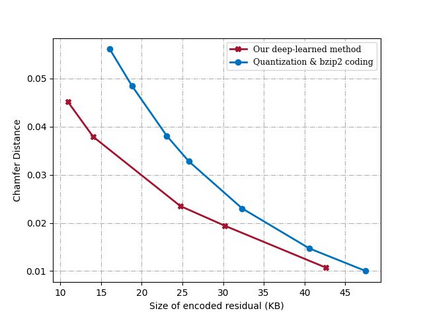
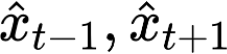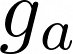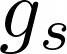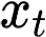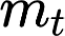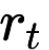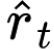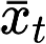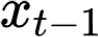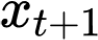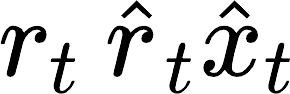The large amount of data collected by LiDAR sensors brings the issue of LiDAR point cloud compression (PCC). Previous works on LiDAR PCC have used range image representations and followed the predictive coding paradigm to create a basic prototype of a coding framework. However, their prediction methods give an inaccurate result due to the negligence of invalid pixels in range images and the omission of future frames in the time step. Moreover, their handcrafted design of residual coding methods could not fully exploit spatial redundancy. To remedy this, we propose a coding framework BIRD-PCC. Our prediction module is aware of the coordinates of invalid pixels in range images and takes a bidirectional scheme. Also, we introduce a deep-learned residual coding module that can further exploit spatial redundancy within a residual frame. Experiments conducted on SemanticKITTI and KITTI-360 datasets show that BIRD-PCC outperforms other methods in most bitrate conditions and generalizes well to unseen environments.
翻译:LiDAR 传感器收集的大量数据带来了LIDAR点云压缩(PCC)问题。LIDAR PCC 先前的工作曾使用范围图像表示法,并遵循预测编码模式来创建一个基本编码框架原型。然而,它们的预测方法由于在范围图像中的无效像素失职和在时间步骤中省略未来框架而产生了不准确的结果。此外,它们的剩余编码方法手工设计无法充分利用空间冗余。为了纠正这一点,我们提议了一个BIRD-PCC编码框架。我们的预测模块了解范围图像中无效像素的坐标,并采用了双向方案。此外,我们引入了一个可以进一步利用剩余框架空间冗余的深层次剩余编码模块。在SemanticKITTI和KITTI-360数据集上进行的实验表明,在多数位化条件下,BIRD-PCC优于其他方法,并且非常概括到看不见的环境。</s>