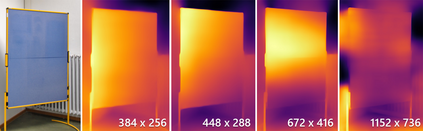
Neural networks have shown great abilities in estimating depth from a single image. However, the inferred depth maps are well below one-megapixel resolution and often lack fine-grained details, which limits their practicality. Our method builds on our analysis on how the input resolution and the scene structure affects depth estimation performance. We demonstrate that there is a trade-off between a consistent scene structure and the high-frequency details, and merge low- and high-resolution estimations to take advantage of this duality using a simple depth merging network. We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multi-megapixel depth maps with a high level of detail using a pre-trained model.
翻译:然而,推断的深度地图远低于一兆像素分辨率,而且往往缺乏精细的细节,从而限制了其实用性。我们的方法基于我们对投入分辨率和场景结构如何影响深度估计性能的分析。我们证明,在一致的场景结构和高频细节之间存在着权衡,并结合了低分辨率和高分辨率估计,以便利用这一双重性,使用简单的深度合并网络。我们提出了一个双重估算方法,改进了全象深度估计,并采用了补丁方法,为最终结果增添了本地细节。我们证明,通过将不同分辨率的估算与不断变化的背景合并,我们可以使用预先培训的模式制作出多兆像素深度图,并具有高度详细性。