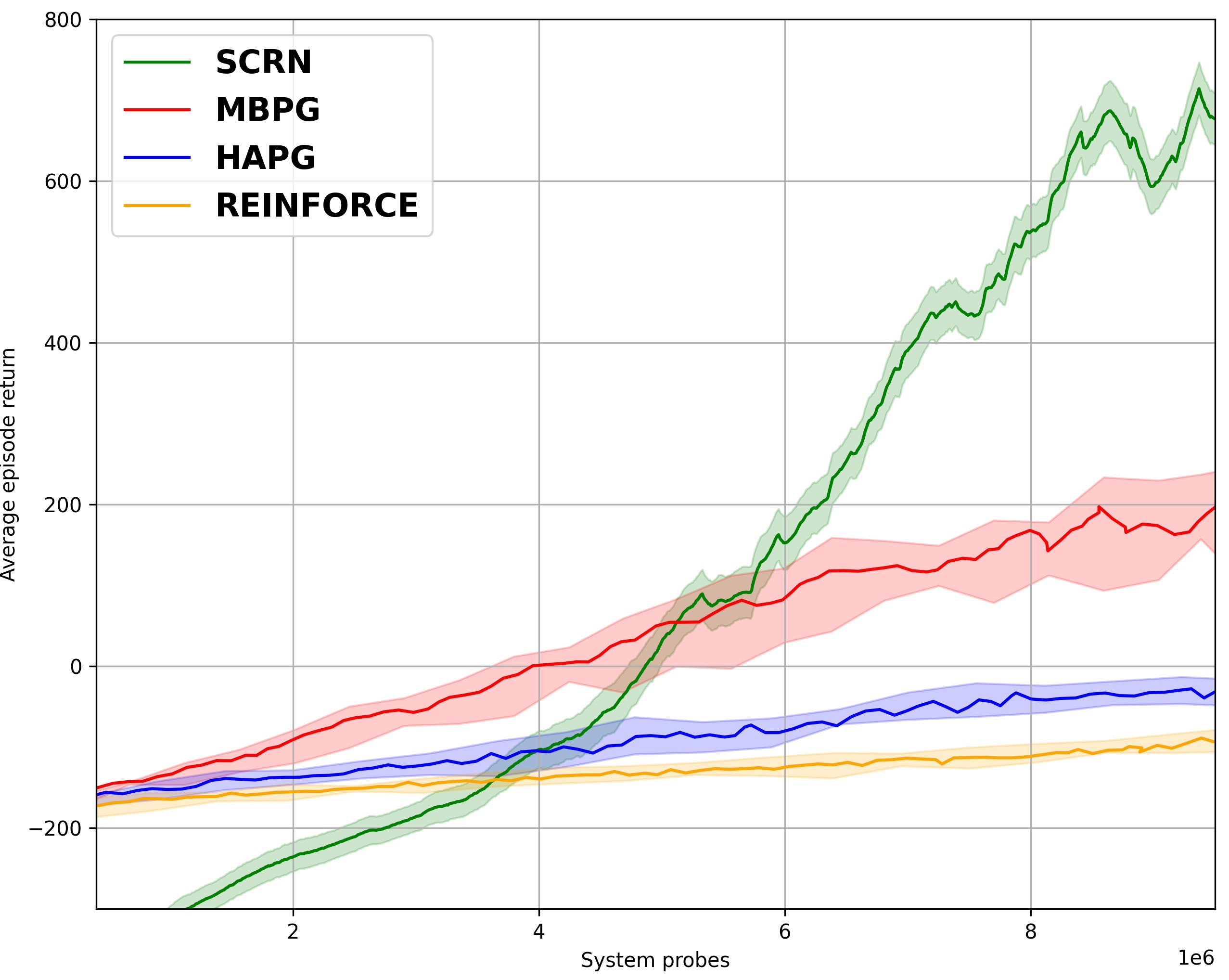
We study the performance of Stochastic Cubic Regularized Newton (SCRN) on a class of functions satisfying gradient dominance property which holds in a wide range of applications in machine learning and signal processing. This condition ensures that any first-order stationary point is a global optimum. We prove that SCRN improves the best-known sample complexity of stochastic gradient descent in achieving $\epsilon$-global optimum by a factor of $\mathcal{O}(\epsilon^{-1/2})$. Even under a weak version of gradient dominance property, which is applicable to policy-based reinforcement learning (RL), SCRN achieves the same improvement over stochastic policy gradient methods. Additionally, we show that the sample complexity of SCRN can be improved by a factor of ${\mathcal{O}}(\epsilon^{-1/2})$ using a variance reduction method with time-varying batch sizes. Experimental results in various RL settings showcase the remarkable performance of SCRN compared to first-order methods.
翻译:我们研究Stochastic Cubic 正规化牛顿(SCRN)在满足梯度主导属性的功能类别方面的表现,该功能类别在机器学习和信号处理方面有着广泛的应用,确保任何一级固定点都是全球最佳的。我们证明,SCRN通过一个因子$\mathcal{O}(\epsilon ⁇ -1/2}),提高了随机梯度梯度梯度下最著名的样本复杂性,以达到美元=epsilon$-全球最佳。即使在一个较弱的梯度主导属性(适用于基于政策的强化学习(RL))下,SCRN也取得了与偏差政策梯度梯度梯度方法相同的改进。此外,我们表明,SCRN的样本复杂性可以用一个因子($_mathcal{O}(\\\\\\\\\\\\\\\\\ 1/2}来改进,使用时间变化批量大小的减差法。各种RL环境的实验结果展示了SCRN相对于一级方法的显著表现。