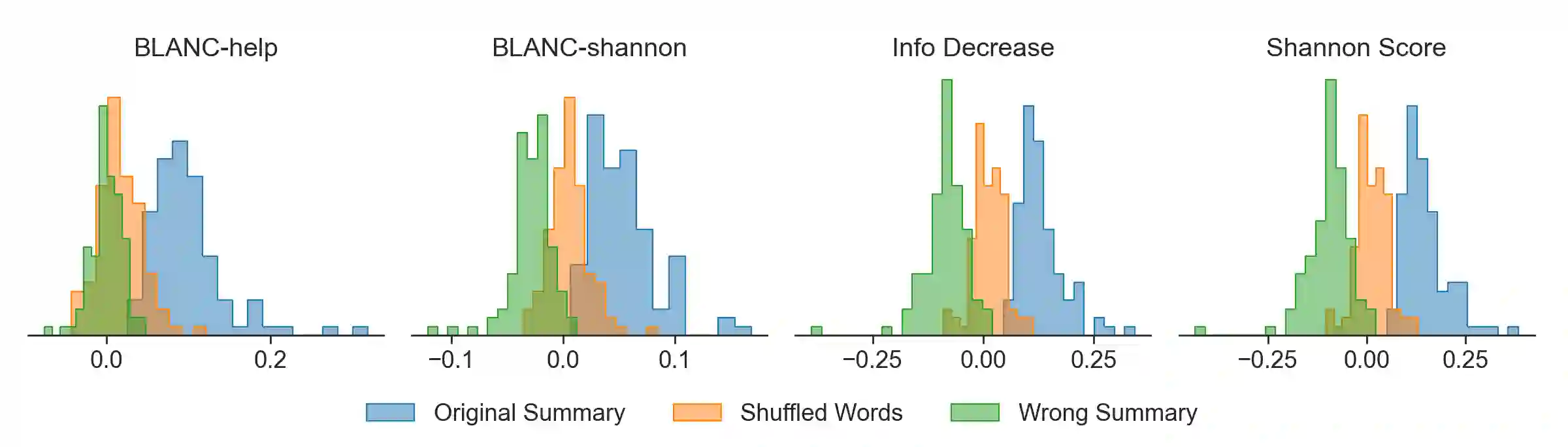
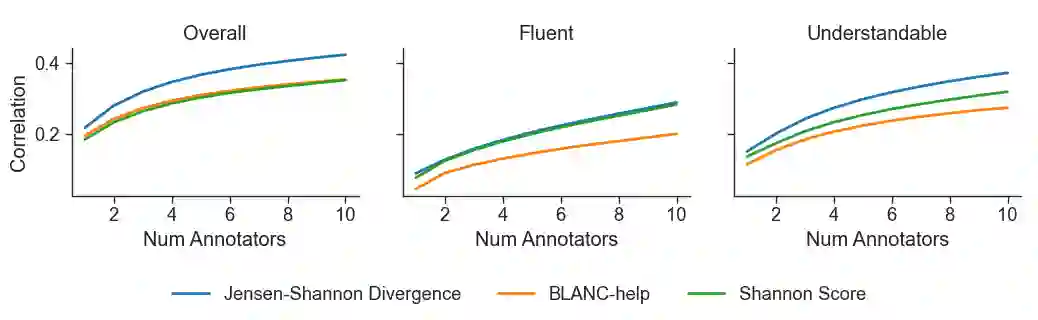
The goal of a summary is to concisely state the most important information in a document. With this principle in mind, we introduce new reference-free summary evaluation metrics that use a pretrained language model to estimate the information shared between a document and its summary. These metrics are a modern take on the Shannon Game, a method for summary quality scoring proposed decades ago, where we replace human annotators with language models. We also view these metrics as an extension of BLANC, a recently proposed approach to summary quality measurement based on the performance of a language model with and without the help of a summary. Using GPT-2, we empirically verify that the introduced metrics correlate with human judgement based on coverage, overall quality, and five summary dimensions.
翻译:摘要的目的是在文件中简明扼要地说明最重要的信息。考虑到这一原则,我们采用新的不附带参考的简要评价指标,使用预先培训的语言模型来估计文件及其摘要之间共享的信息。这些指标是对“香农游戏”的现代分析,这是几十年前提出的一个总结质量评分方法,我们用语言模型取代人类评分器。我们还将这些指标视为BLANC的延伸。BLANC是最近提出的一种根据语言模型的性能和不借助摘要衡量质量的汇总方法。我们利用GPT-2, 实证地证明引入的指标与基于覆盖面、总体质量和五个概要层面的人类判断相关。