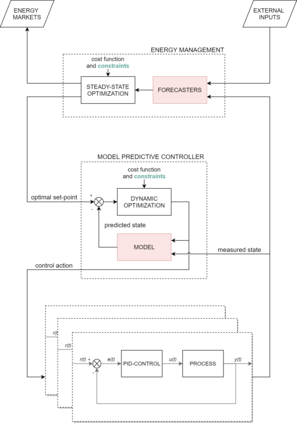
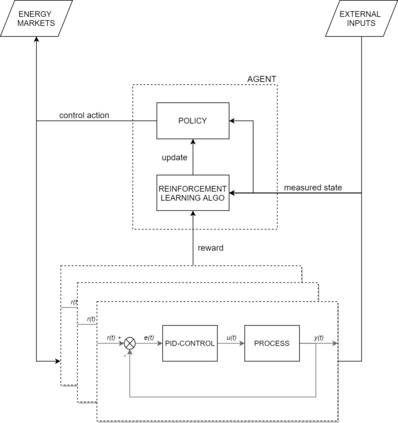
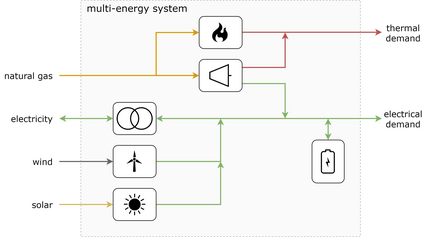
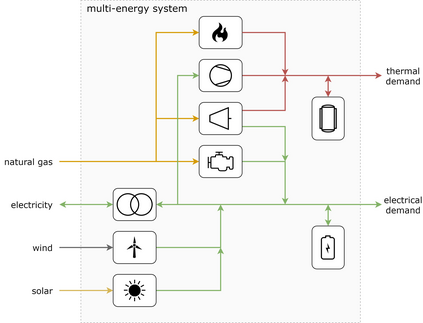
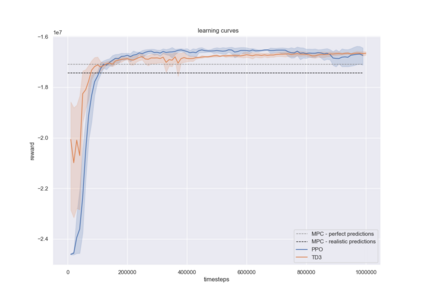
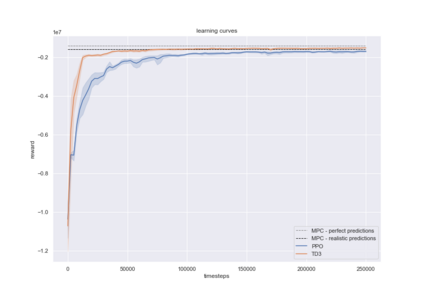
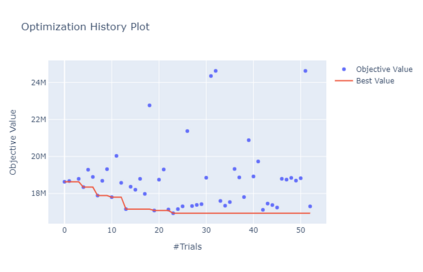
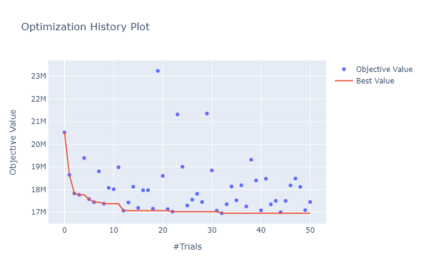
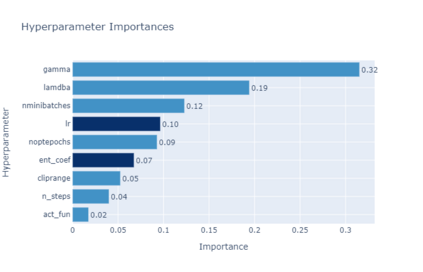
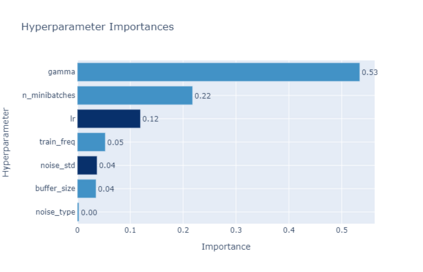
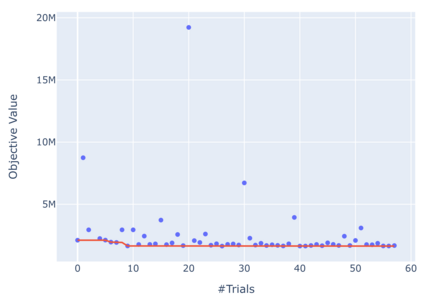
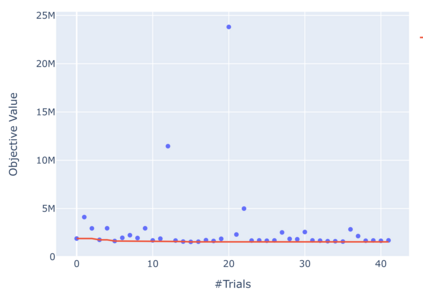
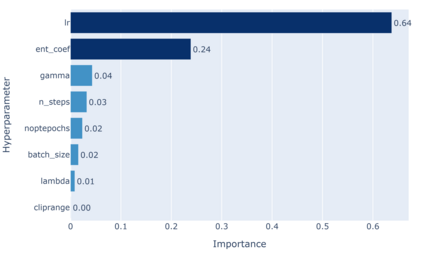
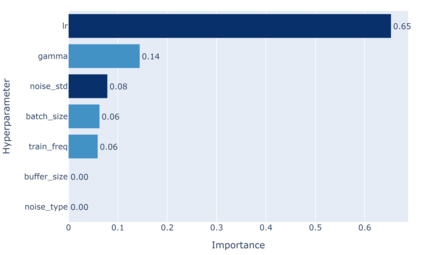
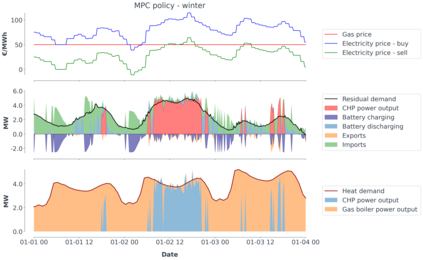
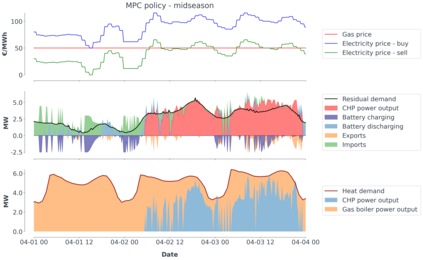
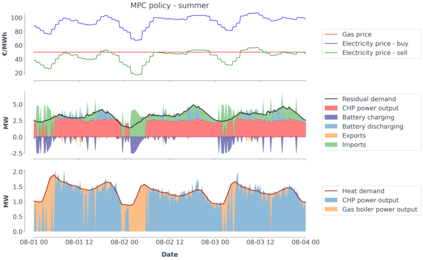
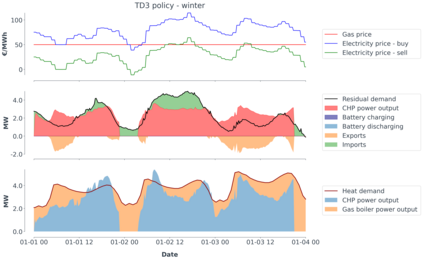
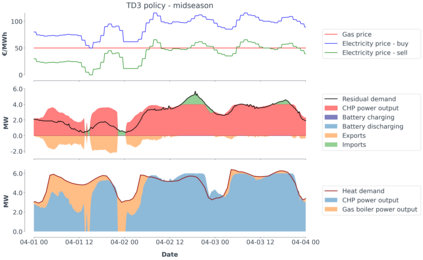
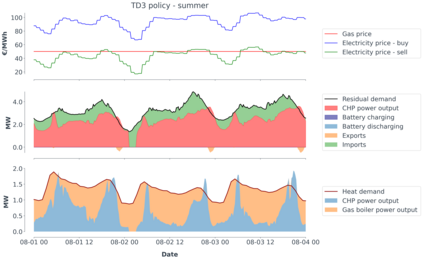
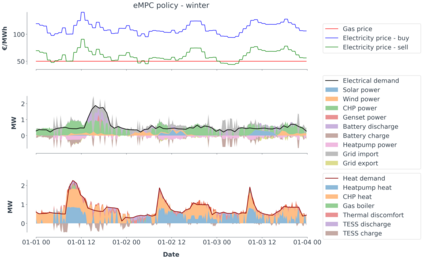
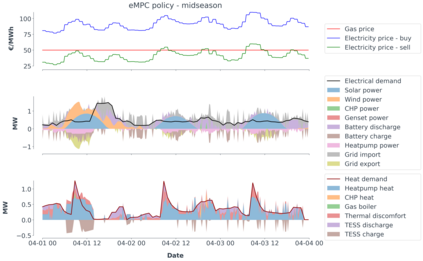
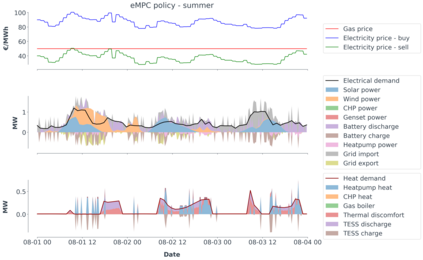
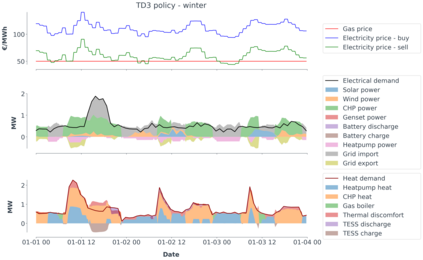
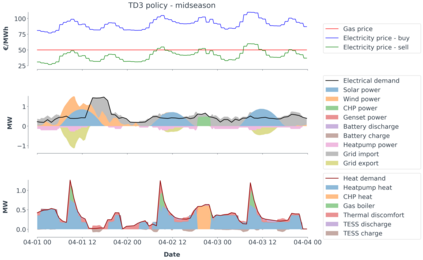
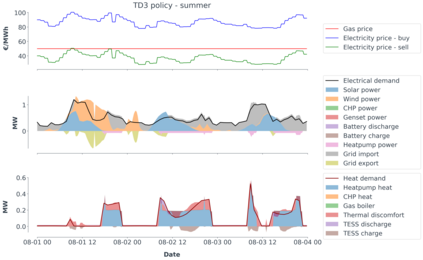
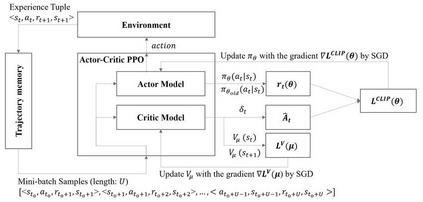
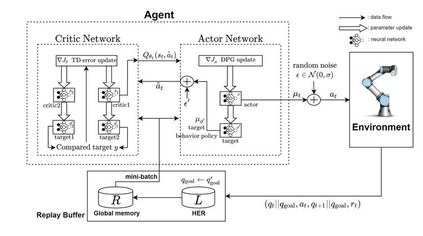
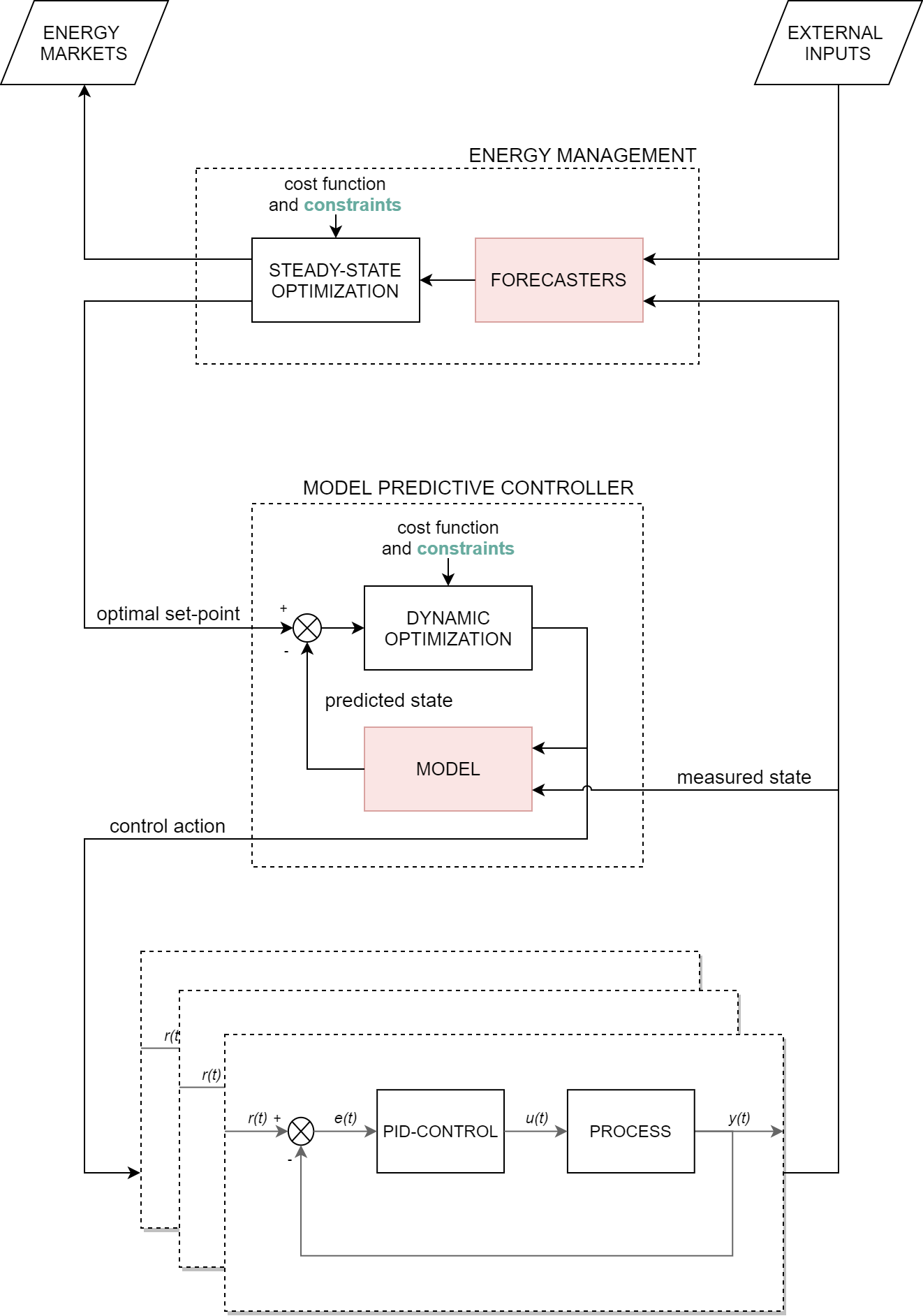
Model-predictive-control (MPC) offers an optimal control technique to establish and ensure that the total operation cost of multi-energy systems remains at a minimum while fulfilling all system constraints. However, this method presumes an adequate model of the underlying system dynamics, which is prone to modelling errors and is not necessarily adaptive. This has an associated initial and ongoing project-specific engineering cost. In this paper, we present an on- and off-policy multi-objective reinforcement learning (RL) approach, that does not assume a model a priori, benchmarking this against a linear MPC (LMPC - to reflect current practice, though non-linear MPC performs better) - both derived from the general optimal control problem, highlighting their differences and similarities. In a simple multi-energy system (MES) configuration case study, we show that a twin delayed deep deterministic policy gradient (TD3) RL agent offers potential to match and outperform the perfect foresight LMPC benchmark (101.5%). This while the realistic LMPC, i.e. imperfect predictions, only achieves 98%. While in a more complex MES system configuration, the RL agent's performance is generally lower (94.6%), yet still better than the realistic LMPC (88.9%). In both case studies, the RL agents outperformed the realistic LMPC after a training period of 2 years using quarterly interactions with the environment. We conclude that reinforcement learning is a viable optimal control technique for multi-energy systems given adequate constraint handling and pre-training, to avoid unsafe interactions and long training periods, as is proposed in fundamental future work.
翻译:模型预测控制(MPC)提供了一种最佳的控制技术,可以确定并确保多能源系统的总运行成本在满足所有系统限制的同时保持在最低水平,然而,这种方法假定了基础系统动态的适当模型,这种模型容易出现建模错误,而且不一定具有适应性。这具有相关的初始和持续项目特定工程成本。在本文件中,我们提出了一种不事先假定一种模型的上和非政策多目标强化学习(RL)多目标学习(RL)方法,这种模型不假定一种前置模式,根据线性多能源系统(LMPC)的总运行成本衡量,以反映当前做法,尽管非线性MPC表现更好)----两者都来自总体最佳控制问题,突出其差异和相似性。在简单的多能源系统配置案例研究中,我们发现,一个双延迟的深度确定性政策梯度(TD3),RL代理商具有匹配和超越完美视野LMPC基准(101.5%)的潜力。虽然现实的LMPC预测,即不完善的季度预测,仅达到98 %。 在更复杂的MEC系统操作周期中,使用更符合现实的LMMMLs 之前的流程,一般的流程,在进行更精确的流程中,在进行更精确的流程前的流程中,在进行更精确的周期内进行更精确的周期内,在进行更精确的学习的 RLMPLMLMT的周期内,在进行更低的周期内,在进行中,在进行更精确的周期内,我们的学习的周期内,在进行更精确的周期里的周期内,在进行更低的周期内,我们的学习了RMPLMT。