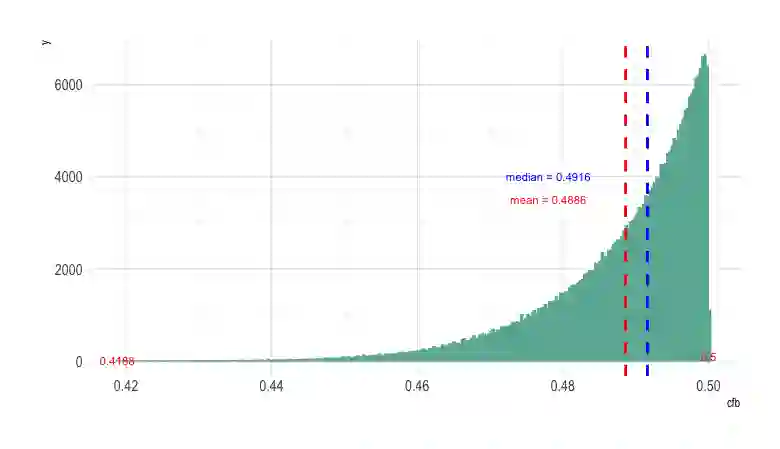
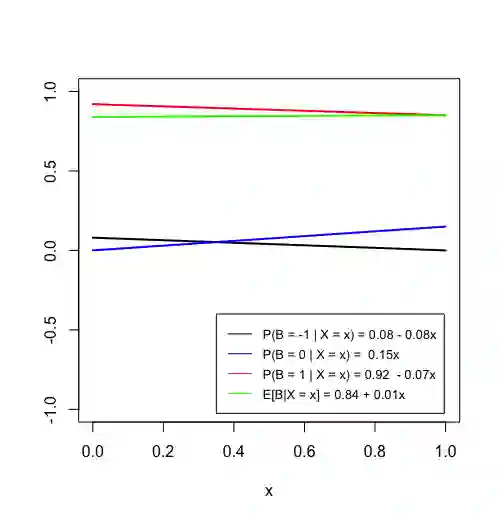
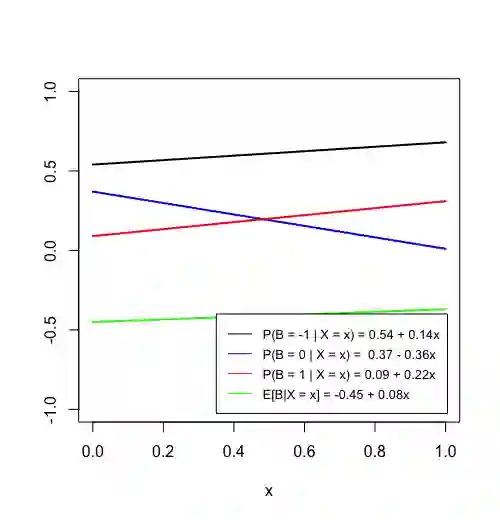
Prediction algorithms that quantify the expected benefit of a given treatment conditional on patient characteristics can critically inform medical decisions. Quantifying the performance of such metrics is an active area of research. A recently proposed metric, the concordance statistic for benefit (cfb), evaluates the discriminatory ability of a treatment benefit predictor by directly extending the concept of the concordance statistic from a risk model for a binary outcome to a model for treatment benefit. In this work, we scrutinize cfb on multiple fronts. Through numerical examples and theoretical developments, we show that cfb is not a proper scoring rule. We also show that it is sensitive to the unestimable correlation between counterfactual outcomes, as well as to the matching algorithms for creating pairs. We argue that measures of statistical dispersion applied to predicted benefit do not suffer from these issues and can be an alternative metric for the discriminatory performance of treatment benefit predictors.
翻译:将特定治疗的预期利益量化的预测算法,如果以病人的特性为条件,就能为医疗决定提供关键的信息。量化这类衡量标准的业绩是一个积极的研究领域。最近提出的一个衡量标准,即 " 协调效益统计 " (cfb),通过将协调统计概念从二元结果的风险模型直接扩大到治疗效益模型,评估治疗福利预测者的歧视性能力。在这项工作中,我们从多个方面仔细查看了分类。通过数字实例和理论发展,我们显示,cfb不是恰当的评分规则。我们还表明,它敏感地认识到反事实结果之间难以估量的相互关系,以及创造配对的匹配算法。我们指出,用于预测效益的统计分散性计量办法不会因这些问题而受到影响,而且可以作为治疗福利预测者歧视性表现的替代指标。