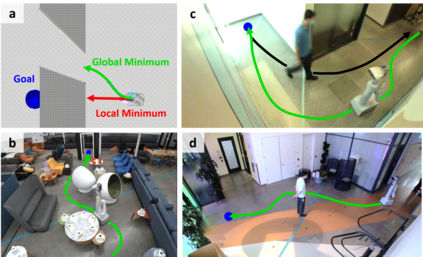
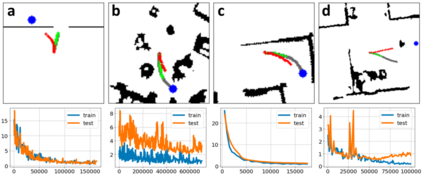
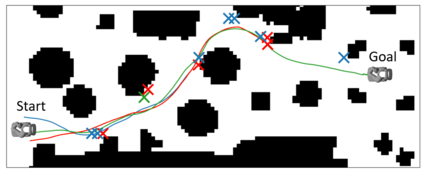
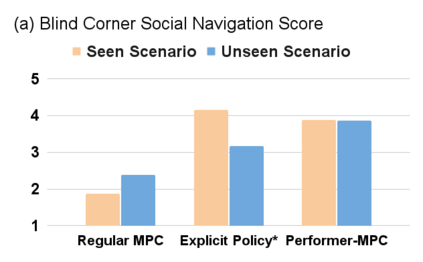
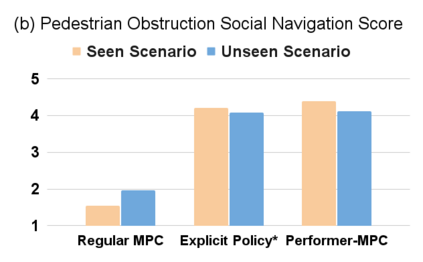
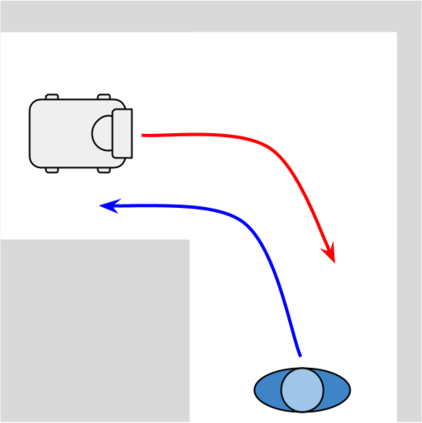
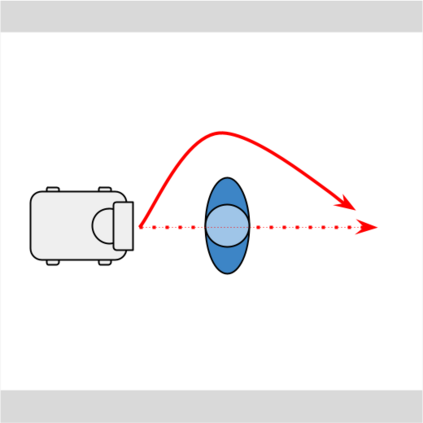
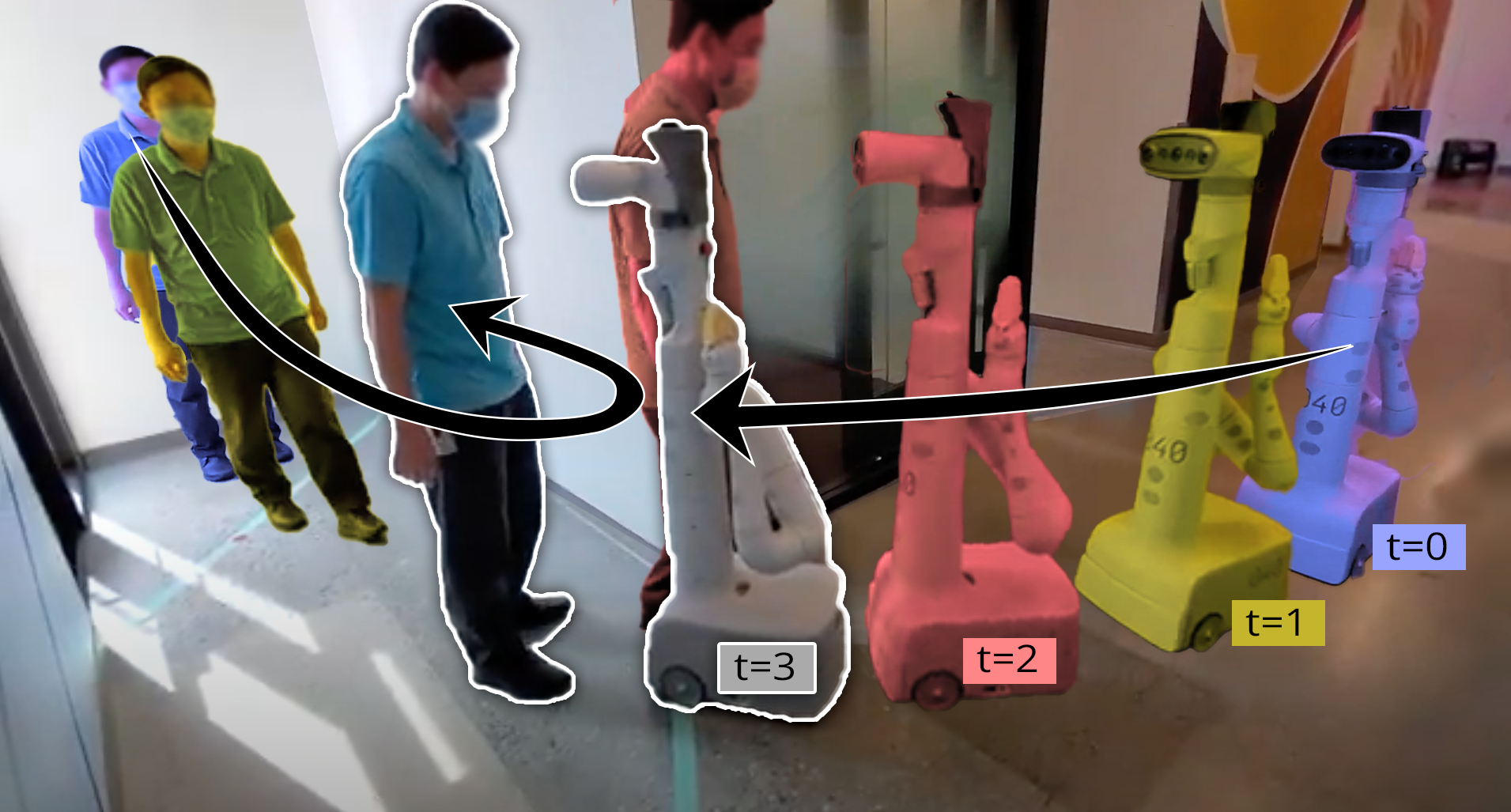
Despite decades of research, existing navigation systems still face real-world challenges when deployed in the wild, e.g., in cluttered home environments or in human-occupied public spaces. To address this, we present a new class of implicit control policies combining the benefits of imitation learning with the robust handling of system constraints from Model Predictive Control (MPC). Our approach, called Performer-MPC, uses a learned cost function parameterized by vision context embeddings provided by Performers -- a low-rank implicit-attention Transformer. We jointly train the cost function and construct the controller relying on it, effectively solving end-to-end the corresponding bi-level optimization problem. We show that the resulting policy improves standard MPC performance by leveraging a few expert demonstrations of the desired navigation behavior in different challenging real-world scenarios. Compared with a standard MPC policy, Performer-MPC achieves >40% better goal reached in cluttered environments and >65% better on social metrics when navigating around humans.
翻译:尽管进行了数十年的研究,但现有的导航系统在野外部署时仍然面临着现实世界的挑战,例如,在封闭的家庭环境或人类占据的公共空间。为了解决这个问题,我们提出了一种新的隐性控制政策,将模仿学习的好处与从模型预测控制(MPC)对系统限制的有力处理结合起来。我们的方法叫做“表演者-MPC”,它使用一种由表演者提供的视觉嵌入环境所测量的学习成本功能参数 -- -- 一个低级隐性注意变异器。我们联合培训成本功能,并构建依赖它的控制器,有效解决相应的双层优化问题。我们表明,由此产生的政策通过利用少数专家展示不同挑战现实世界情景中的理想导航行为,提高了MPC的标准业绩。与标准的MPC政策相比,表演者-MPC实现了在被污染环境中达到的大于40%的目标,在人类周围航行时,超过65%的社会指标。